5 Most Active Apache Big Data Projects
You may have heard of this Apache Hadoop thing, used for Big Data processing along with associated projects like Apache Spark, the new shiny toy in the open source movement. They're among the most active and popular projects under the direction of the Apache Software Foundation (ASF), a non-profit open source steward.
But you may not have heard of lesser-known Big Data projects guided by the ASF that can be equally useful in your development efforts -- projects like Bigtop, REEF and Storm.
Here's a list of the five most active projects listed by the ASF under the "Big Data" category, ranked by a combination of the number of committers and the number of associated Project Management Committee (PMC) members.
Apache Spark
The No. 1 project is the aforementioned Apache Spark. (Strangely, Hadoop is classified under the "Database" category, not "Big Data.") It's probably very familiar, having been covered extensively on this site and virtually every other tech-oriented media outlet. With more than 1,000 code contributors last year, it's been ranked among the most active of ASF projects and open source projects in general.
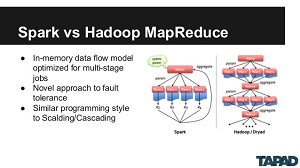 [Click on image for larger view.]
Spark vs. MapReduce (source: Code Project)
[Click on image for larger view.]
Spark vs. MapReduce (source: Code Project)
Described as "fast and general engine for large-scale data processing," it's a red-hot rising star in the open source Big Data ecosystem, bringing performance and superior streaming analytics functionality that surpasses original Hadoop ecosystem components such as MapReduce. It powers libraries such as Spark SQL, Spark Streaming, MLib (machine learning) and GraphX (an API for graphs and graph-parallel computation). With full-on adoption by companies such as IBM, MapR Technologies and Databricks, its committers come from 16 different organizations.
Last year, IBM hopped on the Spark bandwagon in a big way -- promising to put more than 3,500 researchers and developers to work on related projects at labs around the world -- while calling it "potentially the most significant open source project of the next decade."
The Open HUB site lists 31,376 commits made by 1,139 contributors who wrote 821,016 lines of code. The main contributor is Reynold S. Xin, a Databricks developer. The project "took an estimated 228 years of effort (COCOMO model) starting with its first commit in March, 2010 ending with its most recent commit 14 days ago," says Open HUB, an online community and public directory of free and open source software operated by Black Duck Software.
The Spark GitHub site lists 16,001 commits coming from 875 contributors, with Matei Zaharia coming in a close second behind fellow Databricks colleague Xin.
Spark is programmed in Java, Scala and Python, with 44 committers and 35 PMC members. Having moved to version 1.6.1 in March, it can be downloaded here.
Apache Tez
Next up is Tez. (Actually, CouchDB would be No. 2, but I see it belonging to the "Database" category. I was tipped off by this official description: "Apache CouchDB is a database ....")
Tez "is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN." Tez also improves upon the performance of the much-maligned MapReduce, while featuring resource management, simplified deployment and dynamic physical data flow decisions, among many other attributes.
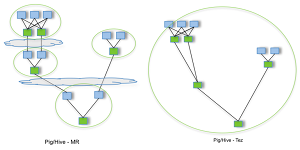 [Click on image for larger view.]
Tez Job Compared with Multiple MapReduce Jobs (source: ASF)
[Click on image for larger view.]
Tez Job Compared with Multiple MapReduce Jobs (source: ASF)
"By allowing projects like Apache Hive and Apache Pig to run a complex DAG [directed acyclic graph] of tasks, Tez can be used to process data, that earlier took multiple MR [MapReduce] jobs, now in a single Tez job," the project site states.
"Apache Tez provides a developer API and framework to write native YARN applications that bridge the spectrum of interactive and batch workloads," Hortonworks says. "It allows those data access applications to work with petabytes of data over thousands nodes. The Apache Tez component library allows developers to create Hadoop applications that integrate natively with Apache Hadoop YARN and perform well within mixed workload clusters."
According to the answer to a Quora question about Tez vs. Spark, a Cloudera developer replied: "Both Tez and Spark provide a distributed execution engine that can handle arbitrary DAGs, targeted towards processing large amounts of data. Both can read and write data to and from Hadoop using any MapReduce input or output format. The main focus of Tez so far has been providing a faster engine than MapReduce under Hadoop's traditional data-processing languages like Hive and Pig."
The Open HUB site says Tez features 185,000 lines of code, coming from 12 current contributors, with the top contributor during the last year listed as Siddharth Seth.
The Tez GitHub site lists 2,136 commits from 15 contributors, led by Hitesh Shah, a Hortonworks developer.
Tez is programmed in Java, sports 34 committers and has 32 members on its PMC. Currently in version 0.8.3, it can be downloaded here.
Apache Bigtop
"Bigtop is ... for infrastructure engineers and data scientists looking for comprehensive packaging, testing and configuration of the leading open source Big Data components," the project site states. "Bigtop supports a wide range of components/projects, including, but not limited to, Hadoop, HBase and Spark."
 [Click on image for larger view.]
Apache Bigtop Primer (source: SlideShare)
[Click on image for larger view.]
Apache Bigtop Primer (source: SlideShare)
According to Bigtop's GitHub site, "The primary goal of Apache Bigtop is to build a community around the packaging and interoperability testing of Apache Hadoop-related projects. This includes testing at various levels (packaging, platform, runtime, upgrade, etc...) developed by a community with a focus on the system as a whole, rather than individual projects."
Running on Linux variants Debian, Ubuntu, CentOS, Fedora, openSUSE and many others, Bigtop has been called "the Fedora of Hadoop" by Cloudera.
"I have been using Apache Bigtop to build selected Hadoop projects customized for my particular needs, developer Christian Tzolov wrote in his technical blog last summer. For example to build RPMs for the newest Spark release or to build specific version of Hue, Flume, Sqoop ... suitable for my Hadoop distro. One can use it to explore incubator projects like Apache Zeppelin and so on."
With the project's affinity for virtualization ("Bigtop provides vagrant recipes, raw images and (work-in-progress) Docker recipes for deploying Hadoop from zero."), Tzolov details using it with a Docker CentOS image.
The Open HUB site says Bigtop is made up of 146,000 lines of code, with 41 current contributors, led by a mysterious "cOs."
The
Bigtop GitHub site lists 1,709 commits stemming from 66 contributors, with Pivotal developer
Roman V. Shaposhnik (379 commits) actually leading "cOs" (226 commits).
Bigtop is programmed in Java, with 32 committers and 24 PMC members. Having hit version 1.1.0 last January, it can be downloaded here.
Apache REEF
"REEF, the Retainable Evaluator Execution Framework, is our approach to simplify and unify the lower layers of Big Data systems on modern resource managers," the project's site states.
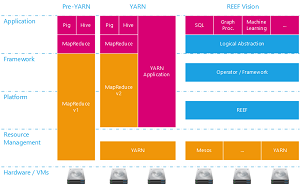 [Click on image for larger view.]
Apache REEF (source: ASF)
[Click on image for larger view.]
Apache REEF (source: ASF)
With the goal of eventually maturing into a Big Data Application Server, "REEF provides a centralized control plane abstraction that can be used to build a decentralized data plane for supporting Big Data systems. Special consideration is given to graph computation and machine learning applications, both of which require data retention on allocated resources to execute multiple passes over the data."
REEF stemmed from the increased programming framework capabilities realized when the YARN resource management software evolved to version 2, being decoupled from the limited MapReduce programming model.
"It is well understood that while enticingly simple and fault-tolerant, the MapReduce model is not ideal for many applications, especially iterative or recursive workloads like machine learning and graph processing, and those that tremendously benefit from main memory (as opposed to disk based) computation," the REEF FAQ states. "A variety of Big Data systems stem from this insight: Microsoft’s Dryad, Apache Spark, Google’s Pregel, CMU’s GraphLab and UCI’s AsterixDB, to name a few. Each of these systems add unique capabilities, but form islands around key functionalities, making it hard to share both data and compute resources between them. YARN, and related resource managers, move us one step closer toward a unified Big Data system stack. The goal of REEF is to provide the next level of detail in this layering."
REEF originated at Microsoft as an effort to improve Big Data application development with any combination of JVM and .NET languages. Having been open sourced in 2013, it's still in heavy use at the Redmond software giant. "Today, REEF forms the backbone of production services such as Azure Stream Analytics and attracts contributions from other teams both from Microsoft and outside," says a Microsoft TechNet blog post from last December, when it graduated to an ASF top-level project. "Further, REEF enables research at several top-tier universities, including at University of Washington, TU Berlin and Seoul National University."
The Open HUB site says REEF has had 3,434 code changes committed by 52 contributors, led by Andrew Chung, who together provided 157,881 lines of code. "Over the past 12 months, 33 developers contributed new code to Apache REEF," the site states. "This is one of the largest open source teams in the world, and is in the top 2 percent of all project teams on Open Hub."
The REEF GitHub site lists the same number of commits, but only 34 contributors, led by Microsoft's Markus Weimer.
REEF is programmed in Java, C# and C++, with 32 committers listed by the ASF and 21 PMC members. Now at version 0.14.0, it can be downloaded here.
Apache Storm
Crashing upon the windswept REEF, Storm is ... sorry, couldn't help it. Storm is actually "a free and open source distributed real-time computation system," according to its Web site. "Storm makes it easy to reliably process unbounded streams of data, doing for real-time processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!"
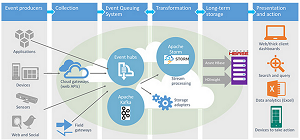 [Click on image for larger view.] Apache Storm
[Click on image for larger view.] Apache Storm
(source: Microsoft)
Boasting fast processing speeds, Storm can be applied to many varied tasks, including real-time stream-processing analytics jobs such as data normalization; server event log monitoring/auditing; online machine learning; continuous computation; and distributed Remote Procedure Calls {RPC), Extract, Transform and Load (ETL); and more.
In answer to a Quora question, FPT Telecom engineer Trie Tan Nguyen said he uses it with Redis, Kafka and Netty to perform real-time analytics. Groupon reportedly uses it to develop real-time data integration systems, and it also is said to power Twitter's publisher analytics, logging every tweet and click to provide raw data to Twitter's publishing partners.
Storm was used to power the original StreamAnalytix software at Impetus Technologies, which in February announced it was adding Spark support to its product. That same month, OpsClarify announced it was supporting Storm -- along with Spark and Kafka -- in its Intelligent Monitoring solution.
The project's Open HUB site says Storm comprises 301,000 lines of code, supplied by 125 current contributors. Robert (Bobby) Evans is listed as the top all-time contributor with 974 commits.
The associated GitHub site lists 6,801 commits from 208 contributors, led by Nathan Marz, a former Twitter developer now reportedly running a stealthy start-up.
Storm is programmed in Java, with 29 committers listed by the ASF and 28 PMC members. Currently at version 0.9.5, it can be downloaded here.
And More
There are many more popular ASF projects related to Big Data, of course, such as Hive, Pig, HBase and others, but, again, the ASF lists them under the "Database" category.
Here I've just examined the most active "Big Data" projects. Others that might deserve your developer consideration, rounding out the top 10, include: Airavata, Drill, Ignite, Phoenix and Scoop, among many others.
Weigh in with your thoughts about open source Big Data projects by commenting here or dropping me a line.
Posted by David Ramel on May 3, 2016