News
Hadoop Survey Shows Spark Coming of Age in 2016
- By David Ramel
- January 20, 2016
Apache Spark, which has been shaking up the Apache Hadoop ecosystem for a couple years now, will come of age this year, moving from a talking point into enterprise deployment, according to a new Hadoop survey from Syncsort Inc.
Interest in Spark dwarfed that of all other compute frameworks, tagged by 67 percent of 267 decision-makers polled in the "Hadoop Perspectives for 2016" survey, representing data architects, IT managers, developers, BI/data analysts and data scientists.
"Nearly 70 percent of respondents are most interested in Apache Spark, surpassing interest in all other compute frameworks, including the recognized incumbent, MapReduce," the survey stated. MapReduce, of course, is an original component of the Hadoop ecosystem, being rapidly subsumed by Spark, which boasts better compute performance and a facility for interactive, streaming and other advanced Big Data analytics.
However, contrary to some sources that claim Spark "could be the end of Hadoop MapReduce," Syncsort still sees a strong,"prevalent" role for MapReduce, which still enjoys a larger installed user base. "While Syncsort expects MapReduce will still be the prevalent compute framework in production, the high level of interest should translate into more Spark deployments, mostly running on Hadoop," the company said in a statement yesterday.
 [Click on image for larger view.]
Views on Hadoop (source: Syncsort)
[Click on image for larger view.]
Views on Hadoop (source: Syncsort)
Hand in hand with the study's main conclusion, Syncsort also predicted more real-time streaming analytics, based on customer feedback in addition to the survey. "More organizations will leverage streaming, real-time data sources," the company said. "The best business decisions often require the most recent data available. Popular use cases include fraud detection, analytics on telemetry and security data, insurance claim validation and the [Internet of Things] IoT."
Syncsort predicted the ascension of newer Hadoop-related technologies such as Spark constitutes a scenario destined to repeat itself. The company said there's a growing interest in new approaches that let enterprises leverage innovations and new platforms without having to replace existing tools or learn new skills.
The Woodcliff Lake, N.J.-based company had some best practices advice for organizations considering Spark with the view of keeping their future options open:
- Allow them to visually design data transformations once and run them anywhere -- across Hadoop, MapReduce, Spark, Linux, Windows, or Unix, on premise or in the cloud -- without the need to recompile or rewrite applications.
- Offer point-and-click interfaces to simply specify the location of multiple data sets and the associated metadata to quickly transfer the data to Spark.
- Run natively in the Apache Spark open-source analytics platform, allowing for full manipulation of the data and the ability to join that data with other data sources for further analysis.
Google Trends Chart Showing Increasing Popularity of Spark
Other non-Spark related conclusions reached by Syncsort from survey results include:
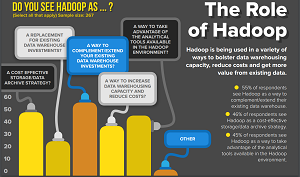
- Offloading from expensive platforms into Hadoop will continue to increase in numbers and scope. 63 percent of respondents feel Hadoop will help them increase business/IT agility, 55 percent expect to increase operational efficiency and reduce costs, and over 51 percent want to leverage it to make more data available for business use across the entire organization. These findings are consistent with Syncsort customer use cases that should continue to gain steam in 2016, including Mainframe and Enterprise Data Warehouse (EDW) offload to Hadoop.
- A growing number of companies will look to leverage Hadoop for advanced use cases. More than half of respondents see Hadoop as a way to innovate, using data from social media and IoT, and applying predictive analytics and visualization for greater insights about their business. Hadoop is yet to be leveraged for mobile apps and software, as only 4.9 percent reported utility for these use cases.
- Data governance and security will be major areas of focus as organizations move to production deployments. More organizations will move towards adopting a "Hadoop first" approach to data management -- skipping traditional and more expensive platforms and applying metadata, lineage, security and other data management measures on Hadoop from the start.
"As Hadoop adoption becomes mainstream, the number of applications in production increases and the use cases, frameworks and data sources become more varied and complex," said Syncsort exec Tendü Yoğurtçu. "Organizations realize significant benefits from Hadoop; however, they also cite challenges in keeping up with new tools and skills, connectivity and data movement, and unforeseen costs. A single software environment to access all enterprise data and manage the entire data pipeline will be critical for organizations to maximize the ROI on their Big Data projects, especially as the demand for real-time analytics in industries such as financial services, healthcare, telecommunications and retail increases."
More on Spark
About the Author
David Ramel is an editor and writer at Converge 360.