News
Big Data Product Watch 2/5/16: App Monitoring, Data Preparation, IoT Hub, More
- By David Ramel
- February 5, 2016
Here's recent news from OpsClarity, Microsoft, Trillium and others, featuring data-driven app monitoring, data preparation/data quality, a Big Data appliance, an Internet of Things (IoT) hub and more.
-
Application monitoring company OpsClarity Inc. yesterday announced that its Intelligent Monitoring solution now works with open source data processing frameworks such as Apache Kafka, Apache Storm, Apache Spark and various associated data stores.
The company said its tool helps developers and others sort out the complexity that comes with using these frameworks and their distributed runtimes. When applying Big Data analytics, companies may use several of these framework, which often comprise multiple components of their own, adding to the complexity of tracking performance and troubleshooting problems.
"Most of these data processing frameworks are themselves a complex collection of several distributed and dynamic components such as producers/consumers and masters/slaves," the company said. "Monitoring and managing these data processing frameworks and how they are dependent on each other is a non-trivial undertaking and usually requires an extremely experienced operations expert to manually identify the individual metrics, chart and plot them, and then correlate events across them."
OpsClarity also provides insight into the supporting data stores of these frameworks, such as Elasticsearch, Cassandra and MongoDB.
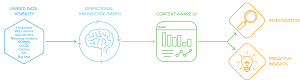 [Click on image for larger view.]
The OpsClarity Platform (source: OpsClarity)
"Unresponsive applications, system failures and operational issues adversely impact customer satisfaction, revenue and brand loyalty for virtually any enterprise today," the company quoted Holger Mueller, analyst at Constellation Research, as saying. "The distributed and complex characteristics of modern data-first applications can add to these issues and make it harder than ever to troubleshoot problems. It is good to see vendors addressing this critical area with approaches that include analytics, data science, and proactive automation of key processes to keep up with the changes being driven by DevOps and Web-scale architectures."
[Click on image for larger view.]
The OpsClarity Platform (source: OpsClarity)
"Unresponsive applications, system failures and operational issues adversely impact customer satisfaction, revenue and brand loyalty for virtually any enterprise today," the company quoted Holger Mueller, analyst at Constellation Research, as saying. "The distributed and complex characteristics of modern data-first applications can add to these issues and make it harder than ever to troubleshoot problems. It is good to see vendors addressing this critical area with approaches that include analytics, data science, and proactive automation of key processes to keep up with the changes being driven by DevOps and Web-scale architectures."
-
Microsoft on Wednesday announced its Power BI suite of business analytics tools now has "publish to Web" capability, letting developers and others create interactive visualizations of data coming from myriad sources and then share those "stories" with others on the Web.
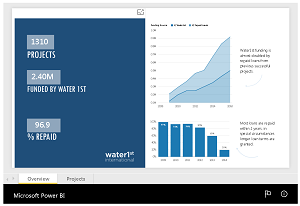 [Click on image for larger view.]
A Microsoft Power BI "Story" (source: Microsoft)
"You can easily embed interactive Power BI visualizations in your blog and Web site or share the stunning visuals through your e-mails or social media communications," Microsoft's Faisal Mohamood said in a blog post. "You can reach millions of users on any device, any place, for an engaging experience."
[Click on image for larger view.]
A Microsoft Power BI "Story" (source: Microsoft)
"You can easily embed interactive Power BI visualizations in your blog and Web site or share the stunning visuals through your e-mails or social media communications," Microsoft's Faisal Mohamood said in a blog post. "You can reach millions of users on any device, any place, for an engaging experience."
Mohamood said the tool -- now in preview -- can help users present their "stories" with new formats and interactive features.
"As the amount of data generated around us continues to accelerate at a blistering pace, there is a tremendous desire and need for the ability to present data in visually engaging ways," he said. "This has influenced the way we tell stories and share data insights online. The best stories are interactive, include rich data and are visual and interactive. A significant number of bloggers, journalists, newspaper columnists, and authors are starting to share data stories with their audience for an immersive experience."
Perhaps the pinnacle example of this movement is the much-publicized article that Bloomberg published last year on the art of software development itself, "What Is Code?" by Paul Ford.
The Power BI visualizations can come from data from almost any source, Mohamood said, including files, databases, applications and public data sources. Authors retain full ownership and management capabilities of the visualizations, which can be auto-refreshed to stay up to date.
- Microsoft also on Wednesday announced the general availability of its Azure IoT Hub, designed to easily and securely connect IoT devices and assets.
"Azure IoT Hub provides an easy and secure way to connect, provision and manage billions of IoT devices sending and receiving trillions of messages per month," Microsoft's Sam George wrote in a Wednesday blog post. "IoT Hub is the bridge between customers' devices and their solutions in the cloud, allowing them to store, analyze and act on that data in real time. IoT Hub enables secure, reliable two-way communication -- from device to cloud and cloud to device -- over open protocols such as MQTT, HTTPS and AMQPS that are already widely used in IoT."
Messages can be tracked to ensure delivery with acknowledgement receipts, and they're sent in a "durable way" to handle devices with intermittent connections.
"Finally, IoT Hub makes it simple to integrate with other Azure services, such as Azure Machine Learning to find deep insights that power IoT businesses, and Azure Stream Analytics to act on those insights in real time by simultaneously monitoring millions of devices and taking action," George said.
- MapR Technologies Inc. announced Wednesday that it had been granted a patent on its Converged Data Platform. That platform integrates Apache Hadoop and Apache Spark to provide real-time database functionality, along with global event streaming, working with enterprise data stores, for developing and operating Big Data applications.
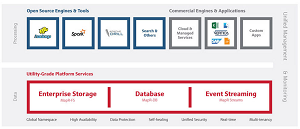 [Click on image for larger view.]
The MapR Converged Data Platform (source: MapR Technologies)
"The awarded patent recognizes the company's fundamental innovation in data architecture that enables real-time and mission-critical application deployments at scale," the company said. "The patented MapR Platform eliminates data silos through the convergence of open source, enterprise storage, NoSQL, and event streams with unparalleled performance, data protection, disaster recovery, and multi-tenancy features."
[Click on image for larger view.]
The MapR Converged Data Platform (source: MapR Technologies)
"The awarded patent recognizes the company's fundamental innovation in data architecture that enables real-time and mission-critical application deployments at scale," the company said. "The patented MapR Platform eliminates data silos through the convergence of open source, enterprise storage, NoSQL, and event streams with unparalleled performance, data protection, disaster recovery, and multi-tenancy features."
The company -- commonly characterized as one of the leading distributors of Hadoop-base analytics solutions -- listed the following key components of the patent claims:
- An architecture based on data structures called "containers" that safeguards against data loss with optimized replication techniques and tolerance for multiple node failures in a cluster.
- Transactional read-write-update semantics with cluster-wide consistency.
- Recovery techniques which reconcile the divergence of replicated data after node failure, even while transactional updates are continuously being added.
- Update techniques that allow extreme performance and scale while supporting familiar APIs.
"The patent details the highly differentiated capabilities of our platform which give us an ongoing technology advantage in the Big Data market," said exec Anil Gadre. "Some of the most demanding enterprises in the world are solving their business challenges using MapR. This is also a great example of how foundational innovation can be combined with open source to enable customers to gain a competitive advantage from the power of a converged data platform."
- Also on Wednesday (a big day for Big Data), Hitachi Data Systems Corp. announced the latest edition of its Hitachi Hyper Scale-Out Platform (HSP). The HSP compute, storage and virtualization appliance now integrates with the Pentaho Enterprise Platform, the company said, to provide a software-defined, hyperconverged platform for deploying Big Data projects.
It's yet another initiative that features the burgeoning IoT as a central player.
"Modern enterprises increasingly need to derive value from massive volumes of data being generated by information technology, operational technology, the IoT and machine-generated data in their environments," the company said in a statement. "HSP offers a software-defined architecture to centralize and support easy storing and processing of these large datasets with high availability, simplified management and a pay-as-you-grow model. Delivered as a fully configured, turnkey appliance, HSP takes hours instead of months to install and support production workloads, and simplifies creation of an elastic data lake that helps customers easily integrate disparate datasets and run advanced analytic workloads."
- Trillium Software on Tuesday announced the launch of Trillium Refine, a new solution designed to optimize Big Data analytics by integrating self-service data preparation with data quality functionality.
"Trillium Refine enables business analysts to gain previously hidden insights into customer behavior, market opportunities, risk exposure and more by joining together a vast universe of complex data and transforming it into accurate and complete information needed to make better business decisions faster than ever before possible," the company said.
The new solution -- available on-premises or in the cloud -- is powered by data preparation technology from UNIFi Software.
The data preparation/data quality capabilities help organizations work with high-volume data from a variety of disparate sources, so they can easily access it, prepare it for analytics further down the pipeline, and improve or enrich it with their own customizations.
Company exec Keith Kohl, in a blog post published yesterday, said the product guides users through the six-step data preparation workflow:
- Selecting which data sets you need to work with.
- Joining all of these data sources.
- Enriching data such as adding a product name and size from a SKU.
- Choosing the columns to work with.
- Filtering out data.
- Aggregating data such as min, max, average, count and count distinct.
After that, he said, "A series data quality steps are used to parse, standardize, match and enrich the data."
About the Author
David Ramel is an editor and writer at Converge 360.