News
IBM, MapR Spur Spark Big Data Development
- By David Ramel
- June 15, 2015
The amazingly active open source Apache Spark project used for Big Data analytics shows no signs of slowing down, as IBM has gone all in on the technology today by promising tons of development support and MapR Technologies Inc. announced tailored Quick Start Solutions to help get started with it.
IBM hopped on the Spark bandwagon in a big way -- promising to put more than 3,500 researchers and developers to work on related projects at labs around the world -- while calling it "potentially the most significant open source project of the next decade."
Big Blue is going to embed Spark into its analytics and commerce platforms and feature it as an IBM Cloud service, it said today from Spark Summit 2015 conference under way in San Francisco. The Armonk, N.Y.-based company is also going to add its IBM SystemML machine learning (ML) technology to the open source Spark ecosystem, the company said in a news release today. And if that's not enough, the company also promised to provide Spark-related education to more than 1 million data scientists and data engineers.
"As data and analytics are embedded into the fabric of business and society -- from popular apps to the Internet of Things (IoT) -- Spark brings essential advances to large-scale data processing," IBM said. "First, it dramatically improves the performance of data dependent apps. Second, it radically simplifies the process of developing intelligent apps, which are fueled by data."
Spark, if you haven't heard by now, is the white-hot open source "cluster computing framework" that provides real-time interactive queries to back more immediate data-based business decisions, faster analysis speeds due to the use of in-memory technologies and a host of other advantages not provided by original Apache Hadoop-related components, such as MapReduce. It has been described as the most active Big Data-related open source project under development and perhaps the most active open source project of any type.
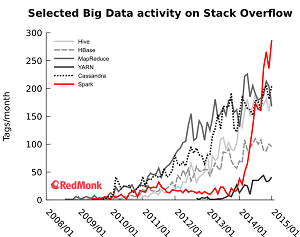 [Click on image for larger view.]
Stack Overflow Activity (source: Redmonk)
[Click on image for larger view.]
Stack Overflow Activity (source: Redmonk)
In fact, commercial steward Databricks Inc. listed some 230 developers who contributed to the recently announced Apache Spark 1.4 version.
"Spark is agile, fast and easy to use," IBM said in announcing its huge Spark investment today. "And because it is open source, it is improved continuously by a worldwide community. Over the course of the next few months, IBM scientists and engineers will work with the Apache Spark open community to rapidly accelerate access to advanced machine learning capabilities and help drive speed-to-innovation in the development of smart business apps. By contributing SystemML, IBM will help data scientists iterate faster to address the changing needs of business and to enable a growing ecosystem of app developers to apply deep intelligence into every thing."
Also today at the Databricks-organized Spark Summit 2015 conference, Hadoop distributor MapR Technologies Inc. announced three new Quick Start Solutions for its Hadoop-based software.
The new solutions target Real-time Security Log Analytics, Time Series Analytics and Genome Sequencing. "These solutions help customers take advantage of the rapid application development and in-memory processing capabilities of the Spark engine along with the enterprise-grade capabilities of the industry-leading Hadoop distribution," MapR said in a news release. "The solutions enable faster development of real-time Big Data applications on log data for security analytics, time-series data for real-time dashboards as well as to build clinical applications on human genome data."
MapR, a sponsor of the Spark Summit 2015 conference (along with IBM), is fresh off another conference where it unveiled its MapR 5.0 Hadoop-based distribution.
The San Jose, Calif.-based company said its Quick Start Solutions provide a quick onramp for organizations to experience the technology and related libraries on the production-grade Hadoop platform and get implementations producing faster.
MapR said the security log analytics solution helps enterprises more quickly detect advanced persistent threats and unknown threats.
The time series solution leverages the company's MapR-DB NoSQL database for rapid ingestion and extraction of data. When combined with real-time aggregation functionality, the solution allows for quick development of monitoring apps and alert systems to work with IoT-style data such as time-series-based data coming from connected "things" such as machines, sensors and devices of various types.
For really large-scale parallel processing, the genome sequencing solution reduces latency and provides other enhancements to enable faster development of lower-cost clinical applications.
"At the core of the Quick Start Solutions is the ability to simplify the process of developing a solution that leverages Spark in conjunction with Hadoop," said exec Sameer Nori in a blog post today. "Each Quick Start Solution includes software, services and training/certification in one powerful package. It comes with prebuilt templates that bring together best practices accumulated by world-class data scientists and data engineers from several Spark and Hadoop deployments."
All three solutions are available immediately.
About the Author
David Ramel is an editor and writer at Converge 360.