News
Splice Machine Open Sources Dual-Engine Big Data Technology
- By David Ramel
- July 18, 2016
Splice Machine Inc. today announced the open sourcing of its Big Data database technology that seeks to leverage the best of the SQL/RDBMS and NoSQL/Hadoop worlds.
Following through on last month's announcement of its intention to go open source, the company has come out with Splice Machine 2.0 in a licensed for-pay enterprise edition and a new free community edition.
The latter free edition -- for which the source code is available on GitHub -- is backed by a new community Web site offering various supporting resources and a new sandbox on the Amazon Web Services Inc. (AWS) cloud, which provides an easy onramp for developers wishing to explore the dual-engine technology.
Those dual engines are Apache Hadoop and Apache Spark, which along with other Apache open source components such as HBase and Kafka form the foundation of Splice Machine 2.0.
"Splice Machine is the open source dual-engine RDBMS for mixed operational and analytical workloads, powered by Hadoop and Spark," the company said. "The Splice Machine RDBMS executes operational workloads on Apache HBase and analytical workloads on Apache Spark."
By incorporating Spark support, the company is utilizing a fast cluster computing framework that has used in-memory technology and other innovations to become one of the most popular open source projects in the Big Data ecosystem.
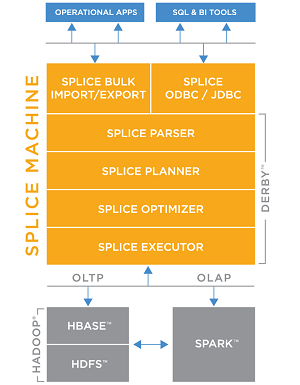 [Click on image for larger view.]
The Splice Machine Stack (source: Splice Machine)
[Click on image for larger view.]
The Splice Machine Stack (source: Splice Machine)
"With the addition of Spark, Splice Machine 2.0 delivers high performance for mixed OLTP and OLAP workloads," the company said last month in announcing its intention to go open source. "It is ideal for a variety of use cases, including: digital marketing, ETL acceleration, operational data lakes, data warehouse offloads, [Internet of Things] IoT applications, Web, mobile, and social applications, and operational applications."
The Spark integration helps the Splice Machine RDBMS take advantage of the best parts of the SQL and NoSQL worlds -- for example, providing ANSI SQL on Hadoop for ACID (Atomicity, Consistency, Isolation, Durability) transactions with scale-out capabilities and in-memory query performance.
The company likened its offering to "lambda architecture in-a-box." Lambda architecture, according to Wikipedia, "is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods."
"We make it very easy to use specialized compute engines for the right workload but do not require the developer to integrate those engines," the company said in explaining the lambda analogy. "Developers can use standard SQL to ingest, access, update, and analyze the database without worrying about what compute engine to use because the Splice Machine optimizer picks the right compute engine, already integrated, based on the nature of the query."
Features of Splice Machine 2.0 highlighted by the company include:
-
Scale-out architecture: Scales out on commodity hardware with proven auto-sharding on HBase and Spark.
- Transactional SQL: Supports full ACID properties in a real-time, concurrent system.
- In-memory technology: Achieves high performance for OLAP queries with in-memory technology from Apache Spark.
- Resource isolation: Allows allocation of CPU and RAM resources to operational and analytical workloads, and enables queries to be prioritized for workload scheduling.
- Management console: A Web UI that allows users to see the queries that are currently running, and to then drill down into each job to see the current progress of the queries, and to identify any potential bottlenecks.
- Compaction optimization: The compaction of storage files is now managed in Spark rather than HBase, providing significant performance enhancements and operational stability.
- Apache Kafka-enabled streaming: Enables the ingestion of real-time data streams.
- Virtual table interfaces: Allows developers and data scientists to use SQL with data that is external to the database, such as Amazon S3, HDFS or Oracle.
The new supporting community Web site features tutorials, videos, a forum for developers, links to community events such as meetups and user group meetings, the source code on GitHub, a StackOverflow tag for seeking help and a Slack channel for communication with other developers.
To help developers try out the technology, the AWS sandbox is offered for cloud-based testing.
"The Splice Machine V2.0 sandbox is powered by Amazon Web Services (AWS) and allows developers to initiate a cluster in minutes," the company said. "The sandbox allows the developer to choose the number of nodes in the cluster and each node's type to accommodate a range of tests, from small to enterprise scale."
On its Get Started site, the company offers three choices to try out the community edition: spin up a Splice Machine cluster on AWS by downloading it through an Amazon E2 account; download it to a machine running Mac OS X or CentOS; or download a cluster edition for running on Cloudera, MapR or Hortonworks Hadoop-based distributions.
"I am very excited about Splice Machine opening its software and developing a community," company co-founder and CEO Monte Zweben said in a statement. "We are committed to making it as easy as possible for developers to get Splice Machine and test it at scale. Our Community edition is a fully functional RDBMS that enables teams to completely evaluate Splice Machine, while our Enterprise edition contains additional DevOps features needed to securely operate Splice Machine, 24×7."
About the Author
David Ramel is an editor and writer at Converge 360.