News
Splice Machine Open Sources Big Data RDBMS
- By David Ramel
- June 7, 2016
Splice Machine Inc., which tackles Big Data analytics with a SQL-based relational database management system (RDBMS) rather than the more common NoSQL approach, is open sourcing its technology, it announced today.
The company claims its flagship, namesake database offering is the industry's first dual-engine RDBMS based on Apache Hadoop and Apache Spark technology, providing Hadoop scalability, Spark in-memory performance, standard SQL and ACID (Atomicity, Consistency, Isolation, Durability) transactions.
Last November it became one of many database vendors joining the Spark parade, leveraging the fast cluster computing framework that has used in-memory technology and other innovations to become one of the most popular open source projects in the Big Data ecosystem.
"The evolution of Splice Machine from being the first transactional RDBMS on Hadoop, to incorporating Apache Spark as an analytical engine, has been amazing to watch as a member of their Advisory Board," said Mike Franklin, former chair of the School of Computer Science at UC Berkeley, and incoming chair of Computer Science at the University of Chicago, in a statement today. "Our AmpLab at Berkeley has initiated many open source projects, including Apache Spark, Apache Mesos and Alluxio (formerly Tachyon). I applaud Splice Machine in taking the leap and joining the open source community."
According to the San Francisco company, its RDBMS features:
-
ANSI SQL-99 coverage, including full DDL and DML.
- ACID transactions with Snapshot Isolation semantics.
- In-place updates that scale from one row to millions with a single transaction.
- Secondary indexing in both unique and non-unique forms.
- Referential integrity, such as Primary and Foreign key constraints.
- Join algorithms like broadcast, merge, batch nested loop and more.
- Resource isolation enabled by a cost-based optimizer.
A key component of the Splice Machine RDBMS offering is Apache HBase, an open source distributed database similar to Google's BigTable, providing real-time updates while running on the Hadoop Distributed File System (HDFS). Today's news release included quotes from a couple of HBase experts.
"Splice Machine has been a long-time contributor to the HBase Community," said Michael Stack, Apache HBase Project Management Committee (PMC) member and engineer at Cloudera. "I am excited to see them joining the open source world and I look forward to helping them through this process."
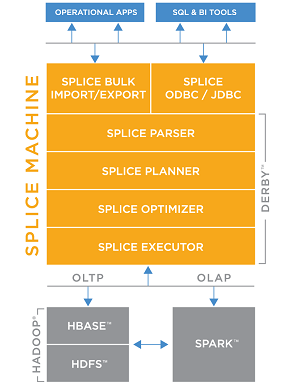 [Click on image for larger view.]
The Splice Machine Stack (source: Splice Machine)
[Click on image for larger view.]
The Splice Machine Stack (source: Splice Machine)
"Splice Machine is pushing boundaries with both HBase and Spark -- for the good of both communities' users," said Nick Dimiduk, PMC member Apache HBase, and author of HBase in Action. "I'm proud to help them take the next step into open source."
That step into open source involves soliciting contributors, mentors and other participants to help with the newly open sourced project, which the company is doing at this site, where it says:
We seek Mentor, Sponsor and Champions to help guide us through the open sourcing process, employing best practices to bring Splice Machine to the community as quickly as possible with high quality. Being a Contributor to Splice Machine positions you as a thought leader in next generation database architecture as part of a wider community of projects such as HBase, Spark and Derby. You will be able to influence the Splice Machine RDBMS and gain early access to new features and architecture, while helping Splice Machine ensure that our next products perform in real-world scenarios and result in real value to your business.
Benefits to community volunteers, the company said, include:
-
Early access to Splice Machine source code.
- Access to computational resources to run Splice Machine.
- Helping to prepare the release for open source.
- Contributing additional features.
- Benchmarking performance.
The site provides a questionnaire to gather more information from potential community contributors.
"We are very excited to make the transition to open source and build a larger community around Splice Machine," said Monte Zweben, co-founder and CEO. "Our whole team is eagerly anticipating the contributions that going open source can enable. We also look forward to being more active within the open source communities beyond our participation around HBase and Spark."
About the Author
David Ramel is an editor and writer at Converge 360.