News
Splice Machine Integrates Spark for Big Data Processing
- By David Ramel
- November 17, 2015
Splice Machine Inc. today announced the integration of Apache Spark technology in the version 2.0 beta edition of its "Hadoop RDBMS" offering.
The San Francisco company is the latest database vendor to join the Spark parade, leveraging the fast cluster computing framework that has used in-memory technology and other innovations to become one of the most popular open source projects in the Big Data ecosystem.
"With the addition of Spark, Splice Machine 2.0 delivers high performance for mixed OLTP and OLAP workloads," the company said in a statement today. "It is ideal for a variety of use cases, including: digital marketing, ETL acceleration, operational data lakes, data warehouse offloads, [Internet of Things] IoT applications, Web, mobile, and social applications, and operational applications."
The company claims its database -- which now marries the scalability of Hadoop and the in-memory performance of Spark, along with support for ANSI standard SQL and ACID transactions -- provides up to 20x faster processing than traditional RDBMS like Oracle and MySQL at one-fourth the cost. The version 2.0 beta comes on the heels of a version 1.5 update last month that added enterprise features.
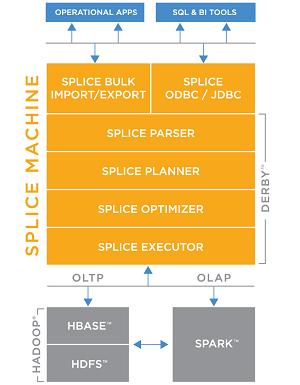 [Click on image for larger view.]
The Splice Machine Stack Now Includes Spark (source: Splice Machine)
[Click on image for larger view.]
The Splice Machine Stack Now Includes Spark (source: Splice Machine)
"The Splice Machine RDBMS is an innovative hybrid of in-memory technology from Spark and disk-based technology from Hadoop," the company said. "Unlike in-memory-only databases, the Splice Machine RDBMS does not force companies to put all of their data in-memory, which can become prohibitively expensive as data volume grows. It uses in-memory computation to materialize the intermediate results of long-running queries but uses the power of HBase to durably store and access data at scale." HBase is an open source distributed database used in Splice Machine instead of the slower, batch-processing MapReduce, an original Hadoop ecosystem component that in some cases has been supplanted by Spark and other newer technologies.
Along with the in-memory capabilities of Spark, Splice Machine said its new database provides Transactional SQL that supports existing OLTP applications without requiring rewrites of existing SQL queries or retraining of developers, along with scale-out architecture on commodity hardware.
"Splice Machine's 2.0 version of its Hadoop RDBMS is a game changer," the company quoted analyst Dr. Robin Bloor of The Bloor Group as saying. "By leveraging the immense scale-out power of Hadoop and the powerful in-memory speed of Spark, businesses can combine analytical and operational systems on one scale-out database without sacrificing performance, eventually performing transactions only when needed."
The company is inviting developers and others to test out the public beta, with details here.
About the Author
David Ramel is an editor and writer at Converge 360.