News
Databricks Previews 'Shiny New Toy': Apache Spark 2.0
- By David Ramel
- May 12, 2016
Two years in the making, Apache Spark 2.0 will officially debut in a few weeks from Databricks Inc., which just released a technical preview so Big Data developers could get their hands on the "shiny new toy" that has become instrumental in processing streaming data.
Spark has achieved enormous popularity, often characterized as the most active Big Data open source project and one of the most active projects in the entire open source community. Databricks, founded by Spark's creators and serving as the main commercial steward of the technology, yesterday announced the technical preview of Spark 2.0 is available in the beta program of the free Community Edition of its cloud-based Big Data platform.
Chief architect Reynold Xin emphasized three key themes for the new release of the game-changing technology, calling it easier, faster and smarter, in a blog post yesterday.
"Since Spark 1.0 came out two years ago, we have heard praises and complaints," Xin said. "Spark 2.0 builds on what we have learned in the past two years, doubling down on what users love and improving on what users lament."
Along with giving developers a hands-on preview, Databricks is using the preview to solicit even more feedback as the go-live countdown continues.
"Whereas the final Apache Spark 2.0 release is still a few weeks away, this technical preview is intended to provide early access to the features in Spark 2.0 based on the upstream codebase," Xin said. "This way, you can satisfy your curiosity to try the shiny new toy, while we get feedback and bug reports early before the final release."
The new features were actually previewed last February when Spark creator and Databricks CTO Matei Zaharia detailed three "exciting" improvements. One is Project Tungsten, which "focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware," in the words of Xin and Josh Rosen. Another is structured streaming, described by Zaharia as "a higher-level streaming API that's built on the Spark SQL engine as well as a lot of the ideas in Spark Streaming." It's also a declarative API that can run on top of Project Tungsten to leverage its optimizations. Finally, Zaharia said he was excited about combining the Dataset and DataFrame APIs. Basically, Spark engineers introduced the two experimental APIs in earlier Spark versions and they now feel comfortable enough with them to combine them to make developers' lives easier -- or at least simpler with respect to Spark APIs.
 [Click on image for larger view.]
The Project Tungsten Performance Boost (source: Databricks Inc.)
[Click on image for larger view.]
The Project Tungsten Performance Boost (source: Databricks Inc.)
In yesterday's post, Xin framed the enhancements conversation around the aforementioned themes of easier, faster and smarter.
The unified APIs are part of the easier theme, along with standard SQL support. "On the SQL side, we have significantly expanded the SQL capabilities of Spark, with the introduction of a new ANSI SQL parser and support for subqueries," he said. "Spark 2.0 can run all the 99 TPC-DS queries, which require many of the SQL:2003 features. Because SQL has been one of the primary interfaces Spark applications use, this extended SQL capabilities drastically reduce the porting effort of legacy applications over to Spark."
On the programming side, he said, other APIs were streamlined in addition to unifying the DataFrames and Datasets APIs. These include SparkSession, "a new entry point that replaces the old SQLContext and HiveContext," and other APIs for machine learning, distributed algorithms in R and more.
For the faster theme, the Tungsten engine comes into play. "This engine builds upon ideas from modern compilers and MPP databases and applies them to data processing," Xin said. "The main idea is to emit optimized bytecode at runtime that collapses the entire query into a single function, eliminating virtual function calls and leveraging CPU registers for intermediate data. We call this technique 'whole-stage code generation.' "
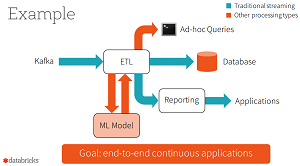
Finally, the aforementioned Structured Streaming APIs constitute the smarter theme. They arose from Databricks' attempting to unify batch and streaming computation. Facilitating streaming analytics was one of the main advantages Spark had over MapReduce, the batch-oriented technology it has basically subsumed. Xin said Databricks discovered that real-world analytics needed more than just a streaming engine.
 [Click on image for larger view.]
Structured Streaming for End-to-End 'Continuous Applications' (source: Databricks Inc.)
[Click on image for larger view.]
Structured Streaming for End-to-End 'Continuous Applications' (source: Databricks Inc.)
"They require deep integration of the batch stack and the streaming stack, integration with external storage systems, as well as the ability to cope with changes in business logic," Xin said. "As a result, enterprises want more than just a streaming engine; instead they need a full stack that enables them to develop end-to-end 'continuous applications.' "
Eschewing the idea of treating everything like a stream and using one programming model to integrate both batched and streaming data, the company came up with a new approach.
"Spark 2.0's Structured Streaming APIs is a novel way to approach streaming," Xin said. "It stems from the realization that the simplest way to compute answers on streams of data is to not having to reason about the fact that it is a stream. This realization came from our experience with programmers who already know how to program static data sets (aka batch) using Spark's powerful DataFrame/Dataset API. The vision of Structured Streaming is to utilize the Catalyst optimizer to discover when it is possible to transparently turn a static program into an incremental execution that works on dynamic, infinite data (aka a stream). When viewed through this structured lens of data -- as discrete table or an infinite table -- you simplify streaming."
Although Spark 2.0 is available in the Community Edition, Xin advised against moving any existing production workloads to the preview package until the upstream 2.0 release is finalized. Developers wanting to access the Community Edition can sign up on a waitlist. They can also register to view a recent webinar that detailed the new improvements.
"Spark users initially came to Spark for its ease-of-use and performance," Xin said. "Spark 2.0 doubles down on these while extending it to support an even wider range of workloads. We hope you will enjoy the work we have put it in, and look forward to your feedback."
About the Author
David Ramel is an editor and writer at Converge 360.