News
3 Things that Excite Spark's Creator Coming in Spark 2.0
- By David Ramel
- February 25, 2016
Matei Zaharia, the creator of Apache Spark, recently detailed three "exciting" improvements to the open source Big Data analytics project coming soon in version 2.
Zaharia started the whole Spark thing pursuing his PhD at UC Berkeley. He's now an assistant professor of computer science at MIT and the CTO of Databricks Inc., a company he co-founded that now serves as the commercial steward of the popular data processing engine.
It was in that latter role that he previewed three major improvements coming to Spark in version 2.0, expected to drop around late April. Speaking at last week's Spark Summit East 2016 conference, Zaharia discussed the three enhancements: phase 2 of Project Tungsten; Structured Streaming; and the unification of the Dataset and DataFrame APIs.
Project Tungsten
This, Zaharia said, speeds up Spark, especially its structured data parts. Introduced last summer in a previous version, Project Tungsten "focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware," according to Databricks bloggers Reynold Xin and Josh Rosen.
"We have some really cool optimizations that are landing in this release that will give speed-ups of 5 to 10x for some really important uses," Zaharia said.
The project came about because CPU speeds haven't kept up with I/O in the past five years or so since Spark was open sourced. It used to be the network and storage components that provided the performance bottleneck in a lot of Big Data applications, Zaharia said. But now those I/O components are far faster, as opposed to the relatively stagnant speeds of CPUs, which now constitute the new performance bottleneck.
 [Click on image for larger view.]
The Project Tungsten Performance Boost (source: Databricks Inc.)
[Click on image for larger view.]
The Project Tungsten Performance Boost (source: Databricks Inc.)
To address that situation, Project Tungsten was born, to get as much of Spark as possible to run closer to the "bare metal," as does native code. It does so primarily in two ways.
"There's native memory management, which bypasses the Java VM, and there's runtime code generation," Zaharia said. "For a lot of high-level libraries, we generate expressions that will run fast on this native memory without creating lots of Java objects."
Structured Streaming
"This is one I'm really excited about," Zaharia said. "This is more on the new API side, but it does some really cool things."
Those cool things are primarily concerned with real-time processing, which Zaharia described as "increasingly important for a lot of Spark users and Big Data users in general."
"But what we discovered talking with users of Spark Streaming is really most applications don't just need to do streaming," Zaharia said. "They're not just like, 'Oh, here's a stream. Apply a map function and get another stream.' Really, the most interesting applications, and the most important ones, combine it with other types of data analysis, including batch and interactive queries. And this is a thing that current streaming engines don't really handle. They're just built for streaming."
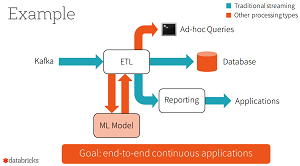 [Click on image for larger view.]
Structured Streaming for End-to-End 'Continuous Applications' (source: Databricks Inc.)
[Click on image for larger view.]
Structured Streaming for End-to-End 'Continuous Applications' (source: Databricks Inc.)
Zaharia said Structured Streaming is "a higher-level streaming API that's built on the Spark SQL engine as well as a lot of the ideas in Spark Streaming." It's also a declarative API that can run on top of Project Tungsten to leverage its optimizations.
The Databricks CTO discussed two scenarios that this applies to. One is the real-time, interactive querying of real-time streaming data, which is something that other engines currently don't do, according to Zaharia. Instead, they typically require moving streaming data to some other location before querying it, which becomes very operationally complex.
The other scenario is training a machine learning (ML) model offline and then applying it to a stream or updating it by using a live stream. For that, Zaharia said, you need an ML library that works across the discrete components -- possibly along with a system that can go back to the offline portion.
"So Spark is obviously very well-suited to do this because it supports all of these types of computations, and in Structured Streaming, we're also looking to make them super easy to combine," Zaharia said.
Structured Streaming can lead to a new class of "continuous applications," which Zaharia described as "end-to-end apps" that can read a stream and then serve queries off it, for example. Spark 2.0 will have an early version of Structured Streaming, focusing on just extract, transform and load (ETL) functionality, with later versions including more operators and libraries.
Combining Dataset and DataFrame APIs
This is the most technical change, Zaharia said, but it provides "a really nice foundation" for the future growth of the project.
Basically, Spark engineers introduced the two experimental APIs in earlier Spark versions and they now feel comfortable enough with them to combine them to make developers' lives easier -- or at least simpler with respect to Spark APIs.
In Spark 2.0, they will be merged so that DataFrames will be just special Datasets with objects of type Row, like this: DataFrame = Dataset[Row]. Though a simple change, Zaharia said it's nice to merge the APIs just to have fewer concepts for users to worry about.
The Resilient Distributed Dataset (RDD) API will remain the low-level API that gives developers the most control over how data is represented, while Datasets and DataFrames provide richer semantics and optimizations. Zaharia said the new libraries will be increasingly used as the interchange format in Spark.
"There are a lot more things coming," Zaharia said in concluding his "whirlwind tour" of upcoming Spark enhancements, "but I hope it gives you an idea of what to be excited about."
You can watch Zaharia's entire presentation on YouTube.
About the Author
David Ramel is an editor and writer at Converge 360.