News
Big Data Benchmark: Google Cloud Dataflow Beats Apache Spark
- By David Ramel
- May 2, 2016
Big Data consultancy Mammoth Data today published a benchmark study that shows Google's Cloud Dataflow service outperforms the extremely popular open source data processing engine, Apache Spark.
Google hired the company to perform the Benchmarking Google Cloud Dataflow study of its fully managed data processing service and programming model. While Dataflow is a paid service, its API was recently accepted by the Apache Software Foundation as an incubation project called Apache Beam, after being submitted early this year.
Even though it was hired by Google for the benchmark report, Mammoth Data -- which touts its own use of Spark in its consultant business -- said it was tasked with performing an objective study. "Given our real-world experience with Hadoop and Spark, Google asked us to 'kick the tires' and share our insight and findings -- both good and bad," the company said.
The good -- for Google -- was at least a doubling of performance across several metrics. "Cloud Dataflow outperformed Spark by 5x with smaller clusters and 2x when using larger clusters," the report states. "Spark did show near linear clock time performance gains as we deployed larger clusters, whereas the Dataflow curve is much more gradual.
"We also noticed that it would take approximately 8x Spark resources to achieve the slowest Dataflow job runtime (128 cores). This is a key point when considering both cost implications and resource capacity planning."
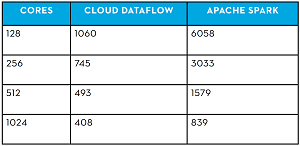 [Click on image for larger view.]
Comparing Clock Time Performance (Time in Seconds) (source: Mammoth Data)
[Click on image for larger view.]
Comparing Clock Time Performance (Time in Seconds) (source: Mammoth Data)
The company also provided observations on respective autoscaling functionality, ease of use and -- of special significance to developers -- programming models.
"One noticeable advantage of Cloud Dataflow over Spark in this use-case is that Spark's built-in windowing functions do not work with 'synthetic' timestamps; you can only window over data based on the time Spark actually receives the data, not a timestamp stored with the data," the report said. "This makes it very difficult to use Spark for working with historical data in batch mode.
"In contrast, the native windowing functions of Cloud Dataflow were straightforward and made implementing the pattern easier. Spark also required some massaging of storing and cache() operations in order not to run out of memory during benchmark runs, whereas Dataflow automatically managed resource optimization -- even on the smaller node clusters."
Mammoth Data didn't use some advanced windowing and trigger concepts of Dataflow, but found its experience to be in line with Google's own programming model comparison published in early February. That in-house comparison stated: "Dataflow provides the flexibility and power necessary for the next generation of real-time data-processing systems, with a clear, practical and robust approach to out-of-order processing. It goes without saying that we're very excited by the possibility of bringing all of this to an even larger audience, thanks to the creation of the Apache Beam incubator project (which, incidentally, includes work from our friends at Cloudera and PayPal to begin bringing the Dataflow model to the Spark runtime)."
Continuing to discuss the programming aspects, Mammoth Data said Dataflow easily integrated with Google's Cloud Storage and Big Query, providing a "batteries included" experience for Google Cloud users. But the news wasn't all one-sided. "However, there are not many custom source and sinks as compared to the greater Hadoop and Spark ecosystem," Mammoth Data said. "Hopefully the Apache Beam efforts will spur new connector work."
Mammoth Data performed three tests: comparing clock time performance with a varying amount of cores; a variance test with smaller instance sizes; and Dataflow with autoscaling.
One area in which it found Dataflow lacking was in ease of use, specifically with its local execution mode contrasted with Spark's read-eval-print loop (REPL), which provides interactive analysis with the Spark Shell. "Dataflow's local execution is great for behavior testing, but it's a poor substitute for the flexibility of using Spark's REPL for interacting with data before creating a standalone application," the report said. The company said it was challenging even getting the benchmark to run on Dataflow, as it wasn't familiar with the API and the service's job-centric model. That provided for a steep onramp, but was beneficial after it was figured out with the help of Stack Overflow.
"While there have been some teething troubles as Google Cloud Dataflow matures, it is already a serious competitor to Apache Spark as well as other cloud Hadoop offerings," Mammoth Data concluded. "Ultimately, Cloud Dataflow provides a flexible and developer-friendly set of APIs as well as a vastly simpler and efficient story for deployment and execution of pipelines. At Mammoth Data, we're excited to have Google opening up its Big Data expertise for all to take advantage."
About the Author
David Ramel is an editor and writer at Converge 360.