News
Google's First Apache Contribution? Dataflow, for Big Data Analytics
- By David Ramel
- January 21, 2016
Google has teamed up with several other companies to submit its open sourced Dataflow technology to the Apache Software Foundation (ASF) as an incubator project, a first for the search giant.
Dataflow is used for defining and executing data processing workflows, including workflows for data ingestion and integration. A data pipeline defined and built with Dataflow's unified model and language-specific SDKs can be executed on several runtimes or execution/processing engines.
This, Google says, relieves the burden of having to rewrite data pipelines in order to use a different engine, such as switching from batch-processing Apache Hadoop MapReduce engine in order to enjoy the superior performance and streaming analytics capabilities of Apache Spark.
"Imagine if every time you upgrade your servers you had to learn a new programming framework and rewrite all your applications," reads a Google blog post that announced the Apache contribution proposal yesterday. "That might sound crazy, but it's what happens with Big Data pipelines."
In seeking to stop such craziness, Google wants to contribute that aforementioned unified model and the Java SDK, along with a set of runners, for further development under the stewardship of the ASF. Runners are client-side abstractions that run pipelines for developers. While Dataflow was open sourced by Google a little more than a year ago, and it has contributed several projects to the open source community under Apache 2.0 licenses, this is the company's first contribution proposal to the ASF.
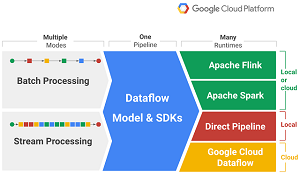 [Click on image for larger view.]
Dataflow (source: Google)
[Click on image for larger view.]
Dataflow (source: Google)
"We believe that submitting Dataflow as an Apache project will provide an immediate, worthwhile and substantial contribution to the open source community," Google said in its incubation proposal. "As an incubating project, we believe Dataflow will have a better opportunity to provide a meaningful contribution to OSS and also integrate with other Apache projects.
"In the long term," the proposal continued, "we believe Dataflow can be a powerful abstraction layer for data processing. By providing an abstraction layer for data pipelines and processing, data workflows can be increasingly portable, resilient to breaking changes in tooling, and compatible across many execution engines, runtimes and open source projects."
Google partnered with several other companies for its proposal, including Cloudera Inc., data Artisans GmbH, Talend Inc., Cask Data Inc. and PayPal Inc. While Google developed Dataflow and its SDK, data Artisans developed the Flink runner, and Cloudera developed the Spark runner. Developers from PayPal and Slack are also initial committers of the project, and Talend exec Jean-Baptiste Onofre champions the project.
Talend will also commit developers to work on the Dataflow framework, focusing on data ingestion and integration, while also working with the community to develop more runners. "Developers leveraging the Dataflow framework won't be 'locked-in' with a specific data processing runtime and will be able to leverage new data processing framework as they emerge without having to rewrite their Dataflow pipelines, making it future-proof," Talend exec Laurent Bride said in a blog post yesterday.
About the Author
David Ramel is an editor and writer at Converge 360.