News
IBM, Google Open Source Machine Learning Technology for Big Data Analytics
- By David Ramel
- December 1, 2015
IBM followed Google's lead in donating machine learning technology to the open source community, providing developers with more resources for their Big Data predictive analytics projects.
IBM last week announced its SystemML technology has been accepted as an incubator project by the Apache Software Foundation (ASF). Now called Apache SystemML, the project "provides declarative large-scale machine learning (ML) that aims at flexible specification of ML algorithms and automatic generation of hybrid runtime plans ranging from single node, in-memory computations, to distributed computations on Apache Hadoop and Apache Spark."
Or, in much simpler words, "System ML enables developers who don't have expertise in machine learning to embed it in their applications once and use it in industry-specific scenarios on a wide variety of computing platforms, from mainframes to smartphones."
Those words came from IBM exec Rob Thomas, who announced the ASF incubator project in a blog post, describing it as a "universal translator for Big Data and machine learning." Machine learning, associated with artificial intelligence and cognitive computing, lets computers learn from data-driven inputs and act on their own to learn from existing algorithms and create new ones to make predictions, for one example.
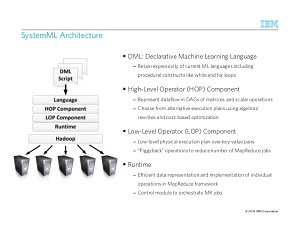 [Click on image for larger view.]
SystemML Architecture (source: IBM)
[Click on image for larger view.]
SystemML Architecture (source: IBM)
IBM in June announced it was open sourcing SystemML as a component of the Apache Spark ecosystem, a rising-star complement to original Apache Hadoop-based technologies. That news was just part of a massive company initiative to buy into and support Spark. IBM promised to put more than 3,500 researchers and developers to work on Spark-related projects at labs around the world -- while calling it "potentially the most significant open source project of the next decade."
In last week's post, Thomas indicated the company has firmed up that "potential" qualification. "We believe that Apache Spark is the most important new open source project in a decade," the IBM exec said. As such, it will get yet another open source component for developers to put in their Big Data analytics toolboxes.
"SystemML allows a developer to write a single machine learning algorithm and automatically scale it up using Spark or Hadoop, another popular open source data analytics tool, saving significant time on behalf of highly skilled developers," Thomas said.
The IBM announcement came only a couple weeks after a similar move by Google, which on Nov. 9 open sourced its TensorFlow technology under an Apache license. TensorFlow stemmed from internal Google "deep learning" technology called DistBelief, a four-year-old project that "has allowed Googlers to build ever larger neural networks and scale training to thousands of cores in our datacenters," according to a Google Research blog post.
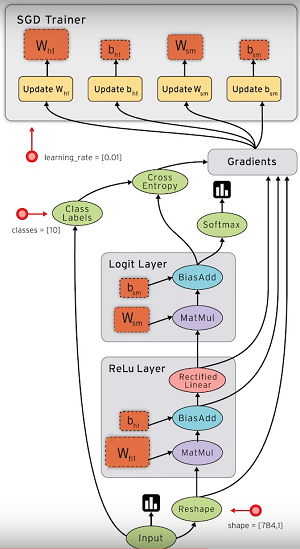 [Click on image for larger view.]
TensorFlow Uses Data Flow Graphs (source: Google)
[Click on image for larger view.]
TensorFlow Uses Data Flow Graphs (source: Google)
"We've used it to demonstrate that concepts like 'cat' can be learned from unlabeled YouTube images, to improve speech recognition in the Google app by 25 percent, and to build image search in Google Photos," reads the blog post written by Jeff Dean and Rajat Monga. "DistBelief also trained the Inception model that won Imagenet's Large Scale Visual Recognition Challenge in 2014, and drove our experiments in automated image captioning as well as DeepDream."
TensorFlow is actually a second-generation iteration of Google's deep learning efforts, improving upon DistBelief, which targeted neural networks only and was tightly coupled to internal Google systems.
"TensorFlow has extensive built-in support for deep learning, but is far more general than that -- any computation that you can express as a computational flow graph, you can compute with TensorFlow," Google said. "Any gradient-based machine learning algorithm will benefit from TensorFlow's auto-differentiation and suite of first-rate optimizers. And it's easy to express your new ideas in TensorFlow via the flexible Python interface."
According to the project's site, TensorFlow is built with a flexible architecture that lets developers use one API to deploy computational workloads to one or more CPUs or GPUs on a mobile device, desktop computer or back-end server.
Google donated the project as a standalone "library for numerical computation using data flow graphs," along with associated tools, tutorials and examples.
"We'll continue to use TensorFlow to serve machine learning in products, and our research team is committed to sharing TensorFlow implementations of our published ideas," Google said.
IBM's Thomas took note of other companies' open source contributions of machine learning technology -- similar to the Google TensorFlow initiative -- while differentiating the benefits of the IBM approach. "While other tech companies have open sourced machine learning technologies as well, most of those are specialized tools to train neural networks," Thomas said. "They are important, but niche, and the ability to ease the use of machine learning within Spark or Hadoop will be critical for machine learning to really become ubiquitous in the long run."
About the Author
David Ramel is an editor and writer at Converge 360.