News
IBM Offers Spark-as-a-Service to Cloud Devs
- By David Ramel
- October 29, 2015
IBM in June said it was investing heavily in Apache Spark development for its Big Data products, this week following up by unveiling a new Spark-as-a-Service offering and announcing a Spark-based redesign of its core analytics solutions.
The company is offering the new managed service to developers using its Bluemix cloud application development platform for creating, running and managing apps and services.
"Offered as a service for developers within the broader ecosystem of IBM's fully managed cloud data services, IBM Analytics for Apache Spark easily integrates with open source, proprietary, and third-party tools on the IBM Bluemix cloud platform," IBM announced this week. "Developers will now be able to infuse analytics into their apps in real-time."
An
Apache Spark Starter offering is now available on the Bluemix catalog, to help "data scientists and data analysts deliver insights and business outcomes through interactive analytics powered by IPython Notebooks, Apache Spark and Object Storage." IBM said the analytics service was launched after a 13-week beta program that involved more than 4,600 developers.
"Apache Spark is an open-source cluster computing framework with in-memory processing to speed analytic applications up to 100 times faster compared to technologies on the market today," says the Web site for the new analytics service. "Developed in the AMPLab at UC Berkeley, Apache Spark can help reduce data interaction complexity, increase processing speed and enhance mission-critical applications with deep intelligence."
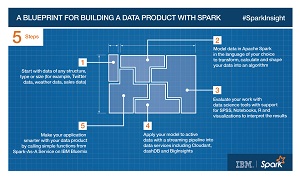 [Click on image for larger view.]
Spark Big Data Development (source: IBM)
[Click on image for larger view.]
Spark Big Data Development (source: IBM)
In its summer announcement, IBM characterized Spark as "potentially the most significant open source project of the next decade" and promised to put more than 3,500 researchers and developers to work on related projects at labs around the world.
This week, the company said it's following through on that initiative, having made more than 60 contributions to the open source Spark project -- including machine learning and SQL-related contributions -- and hiring 35 project contributors for the IBM Spark Technology Center in San Francisco, along with training more than 310,000 data professionals on its BigDataUniversity.com online courses.
Along with the new Spark-as-a-Service, IBM announced it redesigned and simplified the architecture of several software solutions and services using Spark.
"For example, IBM reduced the code base of DataWorks -- the company's popular data preparation and data refinement service -- by over 87 percent, from 40 million lines of code to 5 million lines of code, to simplify operations and dramatically reduce build and deployment times," IBM said. "DataWorks will now benefit directly from Spark's scalability, distributed programming model, and data source connectivity, as well as the frequent enhancements delivered to Spark by the project's contributors."
The company said it also used Spark to boost the real-time processing capabilities of other core analytics and commerce solutions, re-architecting offerings such as IBM BigInsights (Hadoop analytics), IBM Streams (data-in-motion analytics) and IBM SPSS (predictive analytics).
"For data scientists and engineers who want to do more with their data, the power and appeal of open source innovation for technologies like Spark is undeniable," said exec Rob Thomas. "IBM is committed to using Spark as the foundation for its industry-leading analytics platform, and by offering a fully managed Spark service on IBM Bluemix, data professionals can access and analyze their data faster than ever before, with significantly reduced complexity."
About the Author
David Ramel is an editor and writer at Converge 360.