News
DataTorrent Slams Spark, Advocates Open Source Apex
- By David Ramel
- September 16, 2015
The Apache Spark project became the darling of the open source Big Data movement by addressing the shortcomings of original Hadoop ecosystem components such as MapReduce. Now, DataTorrent Inc. is touting its open sourced technology, Project Apex, to fill in what it sees as weaknesses inherent in Spark.
Spark has vaulted into the Big Data limelight by improving upon the batch-processing limitations of MapReduce and offering more versatility -- such as working with multiple data processing engines -- for high-level analytics. It works in conjunction with another Hadoop adjunct, YARN, a resource management platform for working with Hadoop clusters.
Despite being commonly recognized as the most active Big Data open source project -- and rivaling Hadoop itself for Big Data prominence -- Spark has shortcomings, DataTorrent says, that it seeks to address with Apex, which earlier this month was accepted as an incubator project now under the stewardship of the Apache Software Foundation (ASF).
"Spark is not enterprise-grade and suffers from architectural limitations that will leave gaps for a new vendor to solve," said DataTorrent co-founder and CEO Phu Hoang in an e-mail to ADTmag. "Apache Apex, currently in incubation status, is well positioned to compensate for Spark's weaknesses."
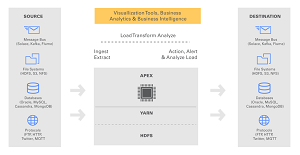 [Click on image for larger view.]
Apex Integration with Other Big Data Components (source: DataTorrent Inc.)
[Click on image for larger view.]
Apex Integration with Other Big Data Components (source: DataTorrent Inc.)
Apex, available on GitHub, is the core technology upon which DataTorrent's commercial offering, DataTorrent RTS 3, along with other technology such as a data ingestion tool called dtIngest, are based.
DataTorrent, founded in 2012 by Hoang and fellow former Yahoo exec Amol Kekre, offered up Apex for open source stewardship by ASF in response to what it said was customer demand for a community to support the core technology behind its commercial product.
One of the benefits of the Apex technology, the company said in its incubator proposal, was that it doesn't require specialized, hard-to-find data science expertise. "Apex is an enterprise-grade native YARN Big Data-in-motion platform that unifies stream processing as well as batch processing," the company said. "Apex processes Big Data in-motion in a highly scalable, highly performant, fault tolerant, stateful, secure, distributed and an easily operable way. It provides a simple API that enables users to write or re-use generic Java code, thereby lowering the expertise needed to write Big Data applications."
Kekre expounded upon the importance of a YARN-native application in a blog post last week introducing Apex as an incubating ASF project, likening the advantages brought by YARN to the increased functionality brought to mobile phones by smartphone technology.
"For the first time, YARN brought the capability of exploring how distributed resources handling Big Data could perform 'a lot of things,' thus going beyond the early MapReduce paradigm, and in a way beyond batch or even compute-going-to-data paradigms," Kekre said. "YARN presented the capability to allow Big Data to not just become big in size, but broader in use cases. With its enabling capability as a Hadoop facilitator, YARN has pushed Hadoop towards realizing its true potential."
Helping in turn to realize Apex's potential is Malhar, a library of operators for use by Big Data developers. "These pre-built operators for data sources and destinations of popular message buses, file systems, and databases, enable organizations to experience accelerated development of business logic," Kekre said. "This reduces the time-to-market significantly, allowing for greater success in developing and launching Big Data projects."
Although DataTorrent said that Malhar makes it easy for developers to integrate projects with Spark, and maintained in its incubation proposal that "the Malhar roadmap includes plans to continue to enhance integration with Apache Spark," the company clearly has Spark in its sights as it offers up Apex to the open source community to attract more developers and increase traction of its commercial enterprise version of DataTorrent RTS 3.
"Enterprises using solutions like Spark are quickly realizing its downfall, in that it's not friendly to data scientists and application developers," Hoang said in his e-mail to ADTmag. "Apache Apex was created in response to customer demand and purpose-built for enterprise needs."
The "big three" commercial Hadoop distributors might disagree, as Cloudera Inc., Hortonworks Inc. and MapR Technologies Inc. all offer Spark in their enterprise-oriented offerings.
Time, and the marketplace, will tell.
About the Author
David Ramel is an editor and writer at Converge 360.