News
Databricks Updates Apache Spark-Based Big Data Platform
- By David Ramel
- August 6, 2015
Databricks Inc., the primary commercial steward of the open source Apache Spark project for Big Data analytics, has upgraded its Spark-based platform, adding support for the R programming language, access control features and more.
Databricks 2.0 comes six weeks after the company -- founded by the original creators of Spark -- announced general availability of the platform. With yesterday's release, the Databricks platform incorporates features of Apache Spark 1.4, announced in June.
Heading those features is support for the R programming language, giving developers another option in addition to Python, Scala and SQL. "Enabling a new category of users to take advantage of Apache Spark -- users will now explore data at scale with R, including one-click visualizations and instant deployment of R code into production," the company said in a statement. The R language has seen increased popularity in the last couple of years for its statistical computing capabilities that help make it a good match for Big Data analytics.
"The explosive growth of popularity for the statistical language R immediately caught our attention -- prompting Databricks to add support for the R programming language in our product," exec Ali Ghodsi said in a blog post yesterday.
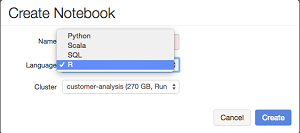 [Click on image for larger view.]
Databricks 2.0 Supports the R Programming Language (source: Databricks Inc.)
[Click on image for larger view.]
Databricks 2.0 Supports the R Programming Language (source: Databricks Inc.)
Databricks also announced features it described as making the platform more suitable for enterprise use, such as new access control functionality that it says improves security and manageability for big development teams with multiple roles and responsibilities. Now, the company said, the access to code and data in notebooks will be controllable on an individual basis.
"The most critical need as organizations scaled was access control," Ghodsi said. "As the adoption of Databricks and Spark gains momentum within an enterprise organization, stakeholders from all functional teams -- marketing, product management, operations, irrespective of domain -- have started to use Databricks to investigate data directly. However, having so many users from diverse teams also means that they would want a way to control the flow of confidential information. To address this need, we built the Access Control feature, which manages the ability of others to read or execute notebook code at the user level."
Of special relevance to developers is a new notebook versioning features that provides "comprehensive support for sophisticated code development processes." That, for example, lets developers manage and track changes to code bases via integration with GitHub and other version control systems. In the Databricks platform, notebooks provide an interactive workspace to developers, allowing for exploration and visualization of data in a collaborative environment.
Also, as enterprises typically run diverse production environments, they can now deploy multiple Spark versions within the Databricks platform, allowing for experimentation while preserving compatibility with existing components.
Apache Spark is often described as the most active Big Data open source project, with more than 500 contributors from more than 200 organizations. Improving upon the batch processing model of the original MapReduce component of the Apache Hadoop ecosystem, Spark allows for more interactive, real-time analytics, with speed enhancements provided by in-memory technology and other optimizations. The general-purpose cluster computing framework has even been described by some as a successor to Hadoop.
With its increasing popularity, Spark has seen development investments from more companies, such as Hortonworks, and more companies, such as MapR Technologies, are incorporating it into their own commercial offerings.
Ghodsi noted that there was still much to do on the open source project and the company's commercial distribution. "There are already many exciting new ideas being worked on, and we promise to share them with you soon!" he said, inviting developer to try out the new platform.
About the Author
David Ramel is an editor and writer at Converge 360.