News
Basho Unveils Simplified Big Data Platform -- Sans Hadoop
- By David Ramel
- May 27, 2015
Add Basho Technologies Inc. to the long list of vendors offering simplified Big Data solutions, but with a twist: no Hadoop included, required or recommended.
Instead, the Basho Data Platform unveiled today is going with Apache Spark, the white-hot open source project that's been positioned by some as an alternative to -- or replacement of -- Apache Hadoop. Hadoop, of course, is the open source project that basically launched the whole Big Data movement and became nearly synonymous with the term "Big Data." Recently, Hadoop has seen its momentum slow, according to some reports, challenged by Spark and other new technologies with improved functionality and performance.
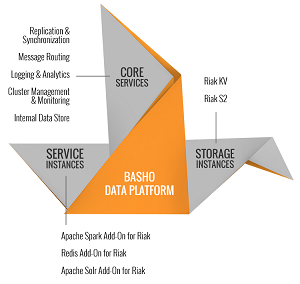
The Basho Data Platform is a prime example of that. The premise of the new platform is providing a comprehensive set of data services by integrating separate technologies, each of which comes with its own complexities, skills requirements and integration challenges.
"The Basho Data Platform has been developed to address these challenges by reducing the complexity of integrating and deploying Big Data application technology components together," the company said in a news release. "It includes NoSQL databases, caching and in-memory analytics, which are required for active workloads. The Basho Data Platform controls the replication and synchronization of data between components of these highly distributed applications and supports multiple database models including key value and object storage. It integrates and simplifies management of Big Data applications for use in public, private and hybrid cloud environments."
 [Click on image for larger view.]
The Basho Data Platform (as Origami) (source: Basho Technologies Inc.)
[Click on image for larger view.]
The Basho Data Platform (as Origami) (source: Basho Technologies Inc.)
The primary component of the Basho platform is the company's own NoSQL distributed database with a new name, Riak KV (it was formerly just Riak). A companion storage component is Riak S2 (formerly Riak CS), for housing large objects in the cloud. In the Basho platform's three-tiered approach, they constitute the platform's "storage instances," which work with "service instances" and "core services."
Among the service instances is Spark, providing fast, in-memory analytics, while a Redis software component provides caching services, handling data served up by Riak KV for faster analytics. Another service instance, Apache Solr, provides full-text search functionality.
Finally, the third tier of the platform, core services, provides deployment, management and synchronization between the storage instances and service instances. The core services tier comprises: replication and synchronization; message routing; logging and analytics; cluster management and monitoring; and an internal data store.
Although the absence of Hadoop and its batch-job-oriented MapReduce component isn't mentioned by Basho in its current platform marketing blitz, the company has addressed the issue in the past. "Every tool has its value," the company said in a 2013 blog post about the differences between Hadoop and Riak. "Hadoop excels at being used by a relatively small subset of the business to answer big questions. Riak excels at being used by a very large number of users and powering critical data for businesses."
More recently, the question came up in an April interview of company CTO Dave McCrory by TechRepublic. "I see Hadoop as something that is becoming the 21st Century data warehouse," McCrory said. "People doing serious work with MapReduce-style problems are flocking to Spark because it's incredibly easy to understand and model, and it's much easier to code against. There are also the incredible performance gains that people are seeing from Spark that isn't hurting either. Spark provides the analytics solution that Hadoop was supposed to deliver on."
Basho said its data platform will be available next month. No pricing information was provided by Basho, which offers a free open source version of Riak on GitHub along with enhanced, for-sale enterprise versions providing perks such as support. The company's Web site says documentation for the new platform is coming soon, but a white paper PDF is available for download upon providing registration information.
About the Author
David Ramel is an editor and writer at Converge 360.