News
Survey: Hadoop Limitations and Variety of Big Data Types Impede Analysis
- By David Ramel
- July 3, 2014
The big problem with Big Data isn't big volume, it's the big variety of data types, according to a survey of data scientists released by Paradigm4 Inc. this week.
"The upshot is that businesses are leaving data -- and money -- on the table," said the computational database company that commissioned a survey of 111 data scientists this spring.
And it turns out Hadoop -- for all its headlines and hype -- isn't much help. Fewer than half of the respondents reported using it or the up-and-coming Spark, an advanced execution engine that improves upon MapReduce.
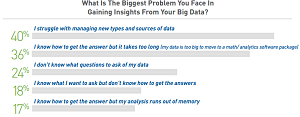
Some three-quarters of the data scientists said Hadoop had serious limitations that impeded productive analysis. "Hadoop is well-suited for embarrassingly parallel problems but falls short for large-scale complex analytics," the report stated. The main obstacle, listed by 39 percent of respondents, was that Hadoop was too difficult to program. Others said it was too slow for interactive, ad hoc queries and real-time analytics.
 [Click on image for larger view.]
What's the Problem? (source: Paradigm4 Inc.)
[Click on image for larger view.]
What's the Problem? (source: Paradigm4 Inc.)
In fact, 35 percent of the data scientists who reported having used Hadoop or Spark said they have stopped using the technologies.
Because of the reported problems, 39 percent of respondents said Big Data made their job more stressful.
"Nearly three-quarters of data scientists -- 71 percent -- said Big Data had made their analytics more difficult and data variety, not volume, was to blame," Paradigm4 said in a statement. "The survey also showed that 36 percent of data scientists say it takes too long to get insights because the data is too big to move to their analytics software. These issues cause data scientists to omit data from analyses and prevent them from maximizing the value of their work."
However, the situation is improving. Hadoop vendors are aware of the issues, the report stated, and are taking steps to alleviate them.
Several projects are underway to add SQL functionality to Big Data products to meet the need for a higher-level query language, instead of forcing users to rely upon Java and other languages to surmount the limitations of MapReduce.
For example, the report stated, Hadoop vendor Cloudera Inc. has discarded MapReduce and is instead offering its Impala tool to facilitate SQL queries on the Hadoop Distributed File System (HDFS).
Paradigm4 concluded its report with some advice for companies. "The fact that so many data scientists identified shortcomings in their infrastructure suggests that the only way to tell which solution is best suited to your organization is to do a pilot project using your data and your use cases," the company said.
The report is available for download with registration for a subscription for "premium content" and newsletters. Paradigm4 is the steward of the open source database SciDB, designed for ad hoc, complex analytics at scale.
About the Author
David Ramel is an editor and writer at Converge 360.