News
Apache Spark Big Data Tool Gets Better SQL Support in Major New Release
- By David Ramel
- June 2, 2014
One of the hottest open source projects in the Big Data/Hadoop ecosystem was upgraded with new SQL functionality and more as the Apache Software Foundation announced the release of Apache Spark 1.0.
Spark is a processing engine for working with data in Hadoop, providing a cluster computing framework for Big Data analytics that improves upon the MapReduce component. Spark improves upon the original, batch-oriented MapReduce technology in several ways, providing support for streaming workloads, in-memory analytics, interactive queries, machine learning and more. Spark reportedly provides up to 100x performance improvements over MapReduce in memory or 10x on disk.
Originally developed in the AMPLab at University of California, Berkeley, the Spark project was recently upgraded to a top-level project at Apache and has been improved by a widespread open source community effort.
"Apache Spark has been dubbed a 'Hadoop Swiss Army knife' for its remarkable speed and ease of use, allowing developers to quickly write applications in Java, Scala, or Python, using its built-in set of over 80 high-level operators," the foundation said in a blog post. "With Spark, programs can run up to 100x faster than Apache Hadoop MapReduce in memory."
Databricks, a company founded by the creators of Spark and a major steward of the project, said the 1.0 release was a "huge milestone" for Spark, which it said was the most active project in the Hadoop ecosystem.
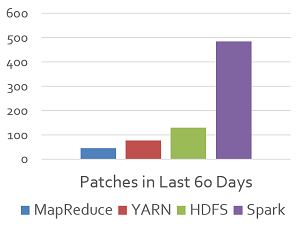 Spark developers have been busy (source: Databricks)
Spark developers have been busy (source: Databricks)
Among the dozens of new features in the release, Databricks emphasized the importance a new module, Spark SQL, which integrates support for SQL queries along with existing Spark code. This eases the process of loading structured data for advanced analytics, "providing a simpler, more agile, and optimized execution engine." The new module will also serve as the back end for future versions of the companion Shark project that provides a distributed SQL query engine for Hadoop.
Apache said the new component -- now in alpha -- "provides support for loading and manipulating structured data in Spark, either from external structured data sources (currently Hive and Parquet) or by adding a schema to an existing RDD [Spark's distributed data sets]. Spark SQL's API interoperates with the RDD data model, allowing users to interleave Spark code with SQL statements. Under the hood, Spark SQL uses the Catalyst optimizer to choose an efficient execution plan, and can automatically push predicates into storage formats like Parquet. In future releases, Spark SQL will also provide a common API to other storage systems."
Databricks said that by blurring the lines between RDDs and relational tables, developers can easily mix SQL commands that query external data with complex analytics within one application. Databricks said the module was developed in view of consistent user requests to more easily import data from external stores, such as Hive.
Another top new feature in Spark 1.0 is integration with the Hadoop/YARN security model. YARN -- sometimes referred to as "yet another resource negotiator" or "MapReduce 2.0" -- is an improved, next-generation data processing framework that "allows Hadoop to be used as a flexible, multi-purpose data processing and analytics platform (free from the limitations of MapReduce)," explained John K. Waters, this site's editor at large.
Spark's integration with the Hadoop/YARN security model means it can authenticate job submissions, transfer Hadoop Distributed File System (HDFS) credentials in a secure way and authenticate inter-component communications.
Databricks said that Spark, now able to run seamlessly in a secured Hadoop cluster, lets users "easily deploy the same application and on a single machine, a Spark cluster, EC2, Mesos, or YARN."
The third major enhancement emphasized by Databricks is support of lambda expressions, recently introduced in Java 8.
"One of Spark's main goals is to make Big Data applications easier to write," Databricks wrote in April when it introduced the new functionality. "Spark has always had concise APIs in Scala and Python, but its Java API was verbose due to the lack of function expressions. With the addition of lambda expressions in Java 8, we've updated Spark's API to transparently support these expressions, while staying compatible with old versions of Java." Java 6 and 7 are supported through the older API. "Lambda expressions are simply a shorthand for anonymous inner classes, so the same API can be used in any Java version," Databricks said.
Along with the new Java 8 support comes increased support for Python. "Spark's Python API has been extended to support several new functions," Apache said. "We've also included several stability improvements in the Python API, particularly for large datasets. PySpark now supports running on YARN as well."
Other new features in version 1.0 include: improvements to the MLlib scalable machine learning library, the GraphX distributed graph system, and the streaming module; guaranteed API stability for core features; operational and packaging improvements; better documentation; and many smaller changes.
Databricks said version 1.0 was developed by more than 110 developers in the past four months, making it the most active Hadoop project and one of the most active projects in the entire Apache realm. According to Apache, Spark was second only to the CloudStack project in the number of commits in the past 12 months, and had the largest number of contributors, totaling 212, a whopping 241 percent year-over-year increase.
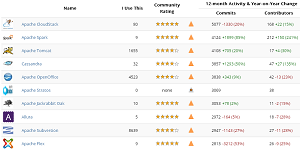 [Click on image for larger view.]
Spark is the second-most-active Apache project
[Click on image for larger view.]
Spark is the second-most-active Apache project
(source: Apache Software Foundation)
With the release of 1.0, Databricks said development on the project will proceed on a quarterly basis for minor releases -- such as 1.1, 1.2 and so on -- with maintenance releases issued as needed to ensure stable versions.
Databricks said Spark 1.0 will be supported in this month's expected release of the Cloudera Hadoop Distribution 5.1. Spark is also part of the Hortonworks distribution and -- as reported here -- the MapR distribution.
More information on the new version 1.0 release will be available at the upcoming Spark Summit 2014 conference. Meanwhile, it's available for download.
About the Author
David Ramel is an editor and writer at Converge 360.