News
Apache Spark 2.1 Improves Structured Streaming
- By David Ramel
- January 11, 2017
Better streaming analytics, a hot topic in Big Data development right now, is the highlight of more than 1,200 improvements and bug fixes in the new Apache Spark 2.1.
Databricks Inc., the commercial steward of the popular open source Spark project, announced the availability of version 2.1 on its platform late last month.
"This release makes measurable strides in the production readiness of Structured Streaming, with added support for event-time watermarks and Apache Kafka 0.10 support," Databricks said. "In addition, the release focuses more on usability, stability, and refinement, resolving over 1,200 tickets, than previous Spark releases."
Streaming analytics, as opposed to the batch-processing model of the original MapReduce component of the Apache Hadoop ecosystem, was one of the main attractions of Spark when it debuted in 2014, along with in-memory processing and other features.
When Spark 2.0 was unveiled last July, Databricks said that version laid the foundation for continuous applications, which provide real-time analytics. That foundation has now been solidified even more.
"Introduced in Spark 2.0, Structured Streaming is a high-level API for building continuous applications," Databricks said. "The main goal is to make it easier to build end-to-end streaming applications, which integrate with storage, serving systems, and batch jobs in a consistent and fault-tolerant way."
New improvements to Structured Streaming in v2.1 include: support for all file-based formats, including JSON, text, Avro, CSV; support for Apache Kafka 0.10, which is often used for ingesting and managing data streams; and event-time watermarks, for identifying events that may be "too late" for the current job.
The new version also addresses the "stringent" visibility and manageability requirements that streaming analytics demands from the underlying systems.
The following figure depicts the concerns usually handled by streaming engines and those needed in continuous applications:
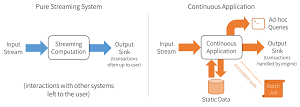 [Click on image for larger view.]
Streaming and Continuous Applications (source: Databricks)
[Click on image for larger view.]
Streaming and Continuous Applications (source: Databricks)
Other highlights of the new release include numerous enhancements to SQL functionality and Spark's core Dataset/DataFrame API, along with better advanced analytics.
The latter improvement stems from many new algorithms that were added to the MLlib machine learning library, the GraphX API for graphs and graph-parallel computation and to SparkR, which provides a package based on the R programming language especially attractive to data scientists running jobs on large datasets from the R shell.
It's Structured Streaming that's the star of the new release, though, and Databricks promised more detailed and hands-on information to come on that technology.
"At Databricks, we religiously believe in dogfooding," the company said. "Using a release candidate version of Spark 2.1, we have ported some of our internal data pipelines, as well as worked with some of our customers to port their production pipelines using Structured Streaming. In coming weeks, we will be publishing a series of blog posts on various aspects of Structured Streaming, as well as our experience with it. Stay tuned for more deep dives."
Interested developers can check out the release notes for more detailed information on the changes brought with Apache Spark 2.1
More on Apache Spark
About the Author
David Ramel is an editor and writer at Converge 360.