News
Popular Big Data Engine Apache Spark 2.0 Released
- By David Ramel
- July 27, 2016
Apache Spark, the widely used open source cluster computing framework featuring a general processing engine for Big Data analytics, has reached version 2.0, the Apache Software Foundation (ASF) announced yesterday.
The widespread popularity of Spark (it's almost like the Pokémon Go of the Apache Hadoop-based Big Data ecosystem) has made it one of the most active open source Big Data projects and even a standout in the entire open source world since being announced in May 2014.
That popularity primarily comes from its improved functionality over original Hadoop component MapReduce, gained by adding support for modern technologies such as in-memory processing, real-time analytics of streaming data, interactive queries, machine learning and more.
Now, that functionality is even better in the first major upgrade since version 1.6 last year.
"Apache Spark 2.0.0 is the first release on the 2.x line," the ASF Spark Web site says. "The major updates are API usability, SQL 2003 support, performance improvements, structured streaming, R UDF support, as well as operational improvements. In addition, this release includes over 2,500 patches from over 300 contributors."
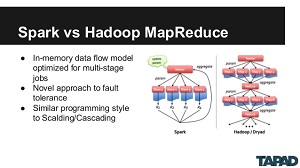 [Click on image for larger view.]
Spark vs. MapReduce (source: Code Project)
[Click on image for larger view.]
Spark vs. MapReduce (source: Code Project)
Databricks Inc., a company founded by the creators of Spark who developed it at UC Berkeley, put a different spin on the improvements of Spark 2.0, framing those improvements with three major themes: easier, faster and smarter.
In a blog post authored by Reynold Xin, Michael Armbrust and Matei Zaharia (the latter being a co-founder of the company and current CTO who is identified on Wikipedia as the "original author" of Spark), Databricks announced it was the first vendor to provide support for the new version.
 [Click on image for larger view.]
What's New (source: Databricks)
[Click on image for larger view.]
What's New (source: Databricks)
While the blog post and ASF Spark Web site provide a comprehensive overview of the new version, Databricks (which in May previewed the "shiny new toy") winnowed down the most notable features in a news release today and provided links for more detailed explanations of some features:
-
Speed: Gaining huge performance in orders of 5 to 10 times faster than Spark 1.6 for some Spark operators due to Tungsten's Phase 2 whole-stage-code generation and Catalyst's code optimization.
- Simplicity: Unifying developer APIs across Spark's libraries such as DataFrames and Datasets.
- Structured Streaming: Laying the foundation for continuous applications by providing high-level declarative streaming APIs based on DataFrames and Datasets built atop Spark SQL engine that works on real-time data.
- Machine Learning Model Persistence: Saving and loading pipelines and models across all programming languages supported by Spark.
- DataFrame-based Machine Learning APIs: Emerging as the primary MLlib package with its "pipeline" APIs and focusing future developments on DataFrame-based API.
- Standard SQL Support: Expanding Spark's SQL capabilities for SQL:2003 features, introducing new ANSI SQL parser, and supporting scalar and predicate type subqueries.
For developers wanting to learn more or jump on the bandwagon (Spark programming primarily is done in the Scala, Java and Python and R languages), the ASF Spark site points out Scala resources such as "First Steps to Scala," "Scala tutorial for Java programmers" and "Programming in Scala." It also provides a "Spark Programming Guide" that features code examples in all three languages.
Databricks also publishes a Spark Hub community site with all kinds of learning resources. It also released a free Community Edition of its Spark-based data platform for learning the technology.
Databricks' Zaharia emphasized the value of developers using those resources and more to put Spark 2.0 through its paces.
"One of the things that's really exciting for me as a developer of Apache Spark is seeing how quickly users start to use new features and APIs we introduce, and in turn, offer almost instantaneous feedback, so that we can continue to improve them," he said.
The ASF credited by name more than 300 contributors to the new release, which can be downloaded here.
More on Spark
About the Author
David Ramel is an editor and writer at Converge 360.