News
Amazon Cloud Handles Data Lake Overhead
- By David Ramel
- August 9, 2019
Data lakes became the de-facto storage scheme for advanced analytics of Big Data as the movement gained traction and enterprises were faced with the problem of housing different types and formats of data to be gleaned for business insights.
Now, for customers of the Amazon Web Services Inc. (AWS) cloud, creating, setting up and managing data lakes is easier as AWS Lake Formation has graduated from preview to become generally available, promising to relieve some of the associated drudgery.
According to AWS: "A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics -- from dashboards and visualizations to Big Data processing, real-time analytics, and machine learning to guide better decisions."
To reduce the complexity of creating a data lake and preparing data for analytics, the new service is designed to simplify and automate typically manual steps such as collecting, cleaning, and cataloging data.
"Customers can easily bring their data into a data lake from a variety of sources using pre-defined templates, automatically classify and prepare the data, and centrally define granular data access policies to govern access by the different groups within an organization," AWS said in a news release.
AWS broke down the process into three main steps:
- Customers must clean and prepare the data -- including partitioning, indexing, and transforming the data -- to optimize the performance and cost that comes with running analytics on the data.
- Then, they have to set up data access roles and enforce security policies across their storage and each of their different analytics engines, and update the security policies when permissions change or new end users are added.
- And, finally, customers are required to make the data available in a secure way to their data analysts so that they can analyze and process the data using any of the available analytics engines.
"These steps require customers to perform a lot of manual work, and as a result, most customers can take up to several months to set up a data lake," AWS said.
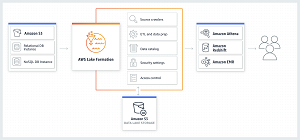 [Click on image for larger view.]
AWS Lake Formation (source: AWS)
[Click on image for larger view.]
AWS Lake Formation (source: AWS)
Most customers use Amazon S3 buckets for data lake storage, and Lake Formation works with several other AWS services including Amazon Redshift (data warehouse), Amazon Athena (serverless interactive query service) and AWS Glue (extract, transform, and load [ETL] service). Support for Apache Spark analytics with Amazon EMR will follow over the next few months, along with Amazon QuickSight (business intelligence service) and Amazon SageMaker (machine learning platform) support.
AWS Lake Formation doesn't incur any extra charges beyond the AWS services used with it, and is initially available in US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland) and Asia Pacific (Tokyo) regions.
More information is available in:
About the Author
David Ramel is an editor and writer at Converge 360.