News
Dataiku Offers No-Code Machine Learning
- By David Ramel
- August 4, 2016
We've covered a lot of low-code/no-code development tools, but they've mostly been relegated to simple app creation, not complicated, cutting-edge technology like machine learning (ML) -- until now.
That's because predictive analytics specialist Dataiku has updated its Dataiku Data Science Studio (DSS) platform to Version 3.1, which it said "unleashes visual machine learning."
Dataiku has introduced five new back-ends for visual ML development with no need for those hard-to-find, expensive developer types well versed in writing programming code.
Much like the numerous mobile development back-ends that take care of tedious chores such as external integrations, database access and so on, those new ML backstops help create predictive ML models.
They include:
-
H2O Sparkling Water: distributed ML and multilayer neural networks (GLM, GBM, Deep Learning, Random Forest, KMeans, Naive Bayes and more).
- Spark MLlib: distributed ML at cluster scale.
- Scikit-Learn: largest library of powerful in-memory Python models.
- XGBoost: fast gradient boosting.
- Vertica ML: in-database learning and scoring.
"Dataiku DSS 3.1 introduces new visual machine learning engines that allow users to create incredibly powerful predictive applications within a code-free interface," the company said in a statement this week. "Users of all skill levels can now leverage HPE Vertica machine learning, H2O Sparkling Water, MLlib, Scikit-Learn and XGBoost directly from within the visual analysis section of Dataiku DSS 3.1 to apply powerful machine learning algorithms to their data science projects without having to write a single line of code."
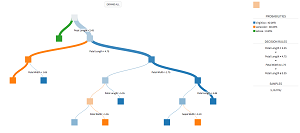 [Click on image for larger view.]
Visual Machine Learning (source: Dataiku)
[Click on image for larger view.]
Visual Machine Learning (source: Dataiku)
Visual capabilities help data jockeys gain new insights into ML models, said Dataiku, which now provides the visualization of trees to better illustrate decision tree, random forest and gradient boosting algorithms, along with the visualization of partial dependency plots for the latter.
DSS 3.1 also adds support for Scala, the increasingly popular programming language used to write the even more popular Apache Spark data processing framework that's quickly becoming a mainstay for Big Data developers.
Dataiku said this support lets data developers/scientists write Spark-native code-based ML transformations while producing data applications, adding to the existing support for Python, R, SQL, Hive, Impala and Pig.
"DSS goes Spark-native with the addition of Scala!" the platform's "What's New" site says. "Scala is the most native language for the Spark ecosystem. It is the only language in which Spark users can write very fast User-Defined functions to work on Dataframes. DSS 3.1 includes a Spark-Scala recipe and an interactive notebook. The recipe features automatic code validation."
Other new features listed by the company in the new release include:
-
New external databases via integration with IBM Netezza, Hana and Big Query.
- Improved UX, with fluid navigation and project dependencies.
- Integration with Tableau so users can extend Dataiku DSS compatibility by creating custom export formats for datasets, including Tableau .tde files.
- An improved DSS home page with the ability to define custom project status and workflow.
- Prebuilt notebook templates with support for PCA, correlations analysis, time series analytics.
- More support for custom algorithms in ML.
- Better preprocessing options in ML.
- The ability to read unlimited Excel files.
"With Dataiku DSS 3.1, we continue to bridge the gap between day to day analytic needs and the latest cutting edge data science technologies," said company CEO and co-founder Florian Douetteau in a statement Monday. "By adding additional machine learning engines and enabling development in Scala, we are bringing even more tools to the table. This allows our users to build the best and most dynamic data science applications -- quickly. All of the new features in this release add to our goal of being a complete, end-to-end platform for the creation, development, and deployment of predictive analytics solutions for any organization."
About the Author
David Ramel is an editor and writer at Converge 360.