News
LinkedIn Open Sources Tech for Mobile, Big Data and Java
- By David Ramel
- July 1, 2016
Seeing as how LinkedIn is all in on open source development, the company is a good fit for its new owner, Microsoft, the poster company for born-again open source evangelism.
Cases in point: the business-oriented social media site this week open sourced technology for building iOS view layouts, analyzing Big Data and detecting URLs with a Java library.
LinkedIn's commitment to open source is such that it devotes a section of its engineering Web site to the topic, explaining the reasons behind its open source philosophy and the business benefits of contributing open code.
"Our engineering team has open sourced more than 75 projects spanning many categories, including data, frameworks, system operations, testing and mobile," the company says on the site. "We believe that open sourcing projects makes our engineers better at what they do best. Engineers grow in their craft by having their work shared with the entire community. Several of our open source projects have gained broad adoption and are now part of the Apache Software Foundation."
New projects that might see strong adoption and ASF stewardship include: LayoutKit, "a fast view layout library for iOS applications"; the updated Gobblin, "the open source universal framework for extracting, transforming, and loading Big Data"; and URL-Detector, "a Java library to detect and normalize URLs in text."
Here's a look at each project:
LayoutKit
This came about because LinkedIn engineers noticed delays in its new LinkedIn iOS app for members. The company investigated the problem (Apple's Auto Layout layout engine), found a solution, put it to work, and on Tuesday announced it was being contributed to the community.
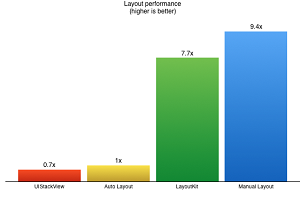 [Click on image for larger view.]
Layout Kit Performance (source: LinkedIn)
[Click on image for larger view.]
Layout Kit Performance (source: LinkedIn)
LinkedIn listed the following benefits of using its declarative LayoutKit library rather than Auto Layout and reasons it's just as easy to use:
-
Fast: LayoutKit is as fast as manual layout code and significantly faster than Auto Layout.
- Asynchronous: Layouts can be computed in a background thread so user interactions are not interrupted.
- Declarative: Layouts are declared with immutable data structures. This makes layout code easier to develop, code review, debug and maintain.
- Cacheable: Layout results are immutable data structures so they can be precomputed in the background and cached to increase user perceived performance.
-
UIKit friendly: LayoutKit produces UIViews and also provides an adapter that makes it easy to use with UITableView and UICollectionView.
- Internationalization: Layouts automatically adjust view frames for right-to-left languages.
- Swift: LayoutKit can be used in Swift applications and playgrounds.
- Tested and production ready: LayoutKit currently has over 90 percent unit test coverage and is being used inside of recent versions of the LinkedIn and LinkedIn Job Search iOS apps.
LinkedIn said its LayoutKit provided immediate performance benefits, finding it was eight times faster and performs similar to manual layout code (an approach eschewed by the company for its complexity and lack of reusability) in certain scenarios.
"LayoutKit is fast because of its specialized layout algorithms and because it does not create UIViews for layouts that do not require them," the company's Nick Snyder said in his Tuesday post announcing the move to open source. "This means that developers are free to compose layouts without hurting performance."
"We are happy to announce that LayoutKit has been released under the Apache 2 license and the code is available on GitHub," Snyder continued. Contributions and suggestions are welcome!"
Gobblin
This Big Data tool was actually open sourced last year but this week received new features in a new release, Gobblin 0.7.0. It's a universal data ingestion framework designed to address data integration problems while ingesting massively scaled data from numerous sources into the Hadoop Distributed File System (HDFS).
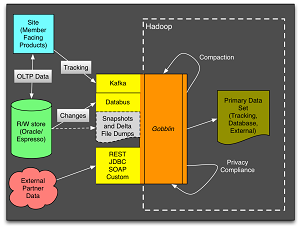 [Click on image for larger view.]
Gobblin (source: LinkedIn)
[Click on image for larger view.]
Gobblin (source: LinkedIn)
"We have described how LinkedIn is using Gobblin to ingest data at massive scale from a variety of sources to HDFS, in many previous blog posts, publications, and talks," said LinkedIn's Vasanth Rajamani in a blog post Wednesday. "Today, we are very excited to introduce several new features in Gobblin's latest release, which are important steps in Gobblin's evolution from a data ingestion tool to a data lifecycle management tool. In addition to ingesting an ever increasing amount of data, the latest release of Gobblin now provides several value-added features around the entire data lifecycle management stack."
Rajamani listed the common requirements LinkedIn was asked to address in order to manage the vast amounts of data that it had learned to successfully ingest for analytics:
-
Can you also copy this data onto these other Hadoop clusters?
- Can you purge some rows for compliance reasons? Can this be done continuously?
- Can the data be automatically registered with Hive, Presto, etc.?
- Can you provide certain datasets in a more optimal format like ORC?
- Can you retain data for a period of time and then purge it on an ongoing basis?
- Can you guarantee that the data doesn't have duplicates?
- Can I easily declare lifecycle management policies that apply to datasets, dataset groups and clusters?
Although not readily related to data ingestion, Rajamani said data ingestion was a prerequisite for these requirements. Rajamani goes on to detail some of the challenges in turning its technology into a data lifecycle management tool, such as simplifying intercluster HDFS replication with Gobblin and dataset configuration management.
"Gobblin 0.7.0 features a JDBC Writer to ingest data into any RDBMS, automatic Hive registration of ingested datasets along with a bunch of other improvements and bug fixes," he said.
URL-Detector
With such a simple goal -- to detect URLs in text and normalize to screen for malware and phishing attack vectors -- there's a surprising amount of complex technical concerns in this project.
For example, early attempts to achieve a solution relied upon regular expressions, resulting in code like this:
((((f|ht)tps?:)?//)?([a-zA-Z0-9!#$%&'*+-/=?^_`{|}~]+(:[^ @:]+)?@)?((([a-zA-Z0-9\\-]
{1,255}|xn--[a-zA-Z0-9\\-]+)\\.)+(xn--[a-zA-Z0-9\\-]+|[a-zA-Z]
{2,6}|\\d{1,3})|localhost|(%[0-9a-fA-F]{2})+|[0-9]+)(:[0-9]{1,5})?([/\\?][^
\\s/]*)*)
Try debugging that. Some attempts by others were even more complex, featuring regexes with more than 5,500 characters, which nobody wants to debug.
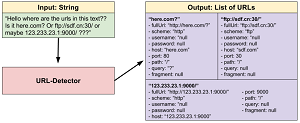 [Click on image for larger view.]
URL-Detector (source: LinkedIn)
[Click on image for larger view.]
URL-Detector (source: LinkedIn)
"Instead of using regular expressions, we hand-built a finite state machine to parse out URLs in text," said LinkedIn engineer Tzu-Han Jan in a blog post yesterday. "A finite state machine is a system consisting of a set of states where each state can transition into other states depending on the input event. In this case, the input event is the current character in the text we are parsing. You can learn more about it here."
Jan said the new tool can detect URLs such as:
-
HTML 5 Scheme -- //www.linkedin.com
- Usernames -- user:[email protected]
- Email -- [email protected]
- IPv4 Address -- 192.168.1.1/hello.html
- IPv4 Octets -- 0x00.0x00.0x00.0x00
- IPv4 Decimal -- http://123123123123/
- IPv6 Address -- ftp://[::]/hello
- IPv4-mapped IPv6 Address -- http://[fe30:4:3:0:192.3.2.1]/
Also, he said, it can detect parts of URLs and handle quote matching and HTML input. The company also found significant performance improvements with URL-Detector over regexes.
More information is available in the "How to Use" section of the project's Readme file on GitHub.
With the Microsoft acquisition, LinkedIn is sure to increase its count of more than 75 open source projects contributed to the community.
"There are many ways to develop an engineering brand -- a signature approach to development that's like a stamp saying: 'We made this,'" said Igor Perisic in explaining LinkedIn's open source strategy. "Open source is a great way to open up code to other developers. It may not be exactly what a team runs in house, but it can definitely show some aspects of the work that went into it. It's also a package that senior individuals can create for candidates to look at. It's an explicit sign from an organization to prospective engineers that they'll not only be able to develop their craft if they work there, but they will be able to reuse the stack that they like instead of having to reinvent it."