News
Koverse Launches 'Data Lake in a Box'
- By David Ramel
- June 22, 2016
Describing its updated Big Data platform as a "data lake in a box," Koverse Inc. offered a guarantee that it can get enterprises up and running to begin gleaning business insights within 30 days.
Touting a patent-pending Universal Indexing Engine, Koverse today announced the release of Koverse Platform Version 2.0.
Koverse said its upgraded platform is a speedier alternative to existing approaches that take too long to derive meaningful analytics results because they're too complex and expensive. It's so sure of its claim that it's offering the 30-day guarantee.
"If we're not done creating your organization's data lake and putting your data into production within 30 days, we'll refund your installation fees," the company says on its Web site. "It's that simple." One caveat: Enterprises must sign on by July 31 to obtain the 30-day guarantee.
Instrumental to the updated platform is the Universal Indexing Engine, used to ingest data. "This breakthrough feature provides thousands of users with real-time, lightning-fast data access covering all fields in all data sets with no advanced configuration for either new or updated data sets," the company said in a statement yesterday.
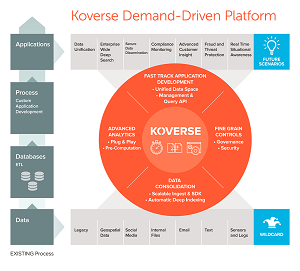 [Click on image for larger view.]
The Koverse Platform (source: Koverse)
[Click on image for larger view.]
The Koverse Platform (source: Koverse)
Koverse said it can help data scientists and developers deploy analytics and use cases with the platform, which facilitates the interrogation of data in real time with unlimited scale while providing granular, built-in security.
Koverse packages a pre-built data lake built on the Apache Hadoop ecosystem, leveraging open source technology such as Apache Spark, Apache Accumulo, Apache MapReduce, Apache ZooKeeper, the Hadoop Distributed File System (HDFS), and a Postgres database. It also features a Koverse Web server and a Koverse Thrift Server working with Thrift clients to provide functionality such as access control, auditing, indexing, querying, auto suggesting and more.
Along with the Universal Indexing Engine for data ingestion, other highlights of the new release listed by the company include:
-
Data import wizard: Data ingestion into the data lake is now a self-service feature, eliminating the need for any special configurations, development, data characterization or help from system administrators to ingest new data sources.
- Self-service forensic search: Forensic search can be used by anyone in an organization to get the data they need for a specific problem or question, securely, within seconds via a simple and scalable search interface.
- Flexible organization of data sets: Koverse customers are frequently importing hundreds of data sets, and it now allows flexibility in grouping and naming of data sets for greater ease of use.
- Tableau, Excel, Python, Spark, SQL and H2O integration: Users and data scientists/developers can now use a range of industry-standard tools to securely and efficiently tap into data in Koverse directly from their preferred environments and push data back into Koverse for broader consumption.
"Koverse reduces the complexity and inefficiencies of putting Big Data into production across an organization," exec Jon Matsuo said. "Simply put, we make data work and we are confident that we can make it work for any organization in one month or less. We are moving the concept of data lake from marketing hype to reality and our growing customer base is a validation of that."
Koverse Data Platform 2.0 is now available, coming as a free upgrade for existing customers and offered in a trial version for new customers.
About the Author
David Ramel is an editor and writer at Converge 360.