News
Microsoft, MapR Lead Spark Charge
- By David Ramel
- June 6, 2016
The Spark Summit conference is now underway in San Francisco, where Microsoft and MapR Technologies Inc. are leading the charge of new product announcements based on the popular open source Big Data analytics technology.
With commercial Apache Spark steward Databricks Inc. having recently set the stage for this week's flurry of announcements by previewing the "shiny new toy" -- the upcoming Apache Spark 2.0 release -- Microsoft announced Spark for Azure HDInsight, while MapR announced a dedicated, enterprise-grade Spark distribution. Several other companies are also weighing in with new Spark-based products and initiatives.
Apache Spark v1.6.1 for Azure HDInsight
Although Spark is on the verge of version 2.0, it's version 1.6.1 underlying Microsoft's Spark for Azure HDInsight, the managed cloud service that leverages Apache Hadoop and Spark running on the Hortonworks Data Platform.
In announcing the general availability of Apache Spark v1.6.1 for Azure HDInsight, Microsoft's Oliver Chiu in a blog post today provided a handy reminder of exactly what the technology provides to the modern Big Data analytics landscape for the few who might still be uninitiated:
Apache Spark is an open source processing framework that runs large-scale data analytics applications in-memory. This allows Spark to deliver queries up to 100 times faster than traditional big data solutions, along with a common execution model for various tasks like extract-transform-load (ETL) processes, batch queries, interactive queries, real-time streaming, machine learning, and graph processing on data stored.
The Azure HDInsight service, in public preview since last July, "offers customers an enterprise-ready Spark solution that's fully managed, secured, and highly available and made simpler for users with compelling and interactive experiences," Chiu said.
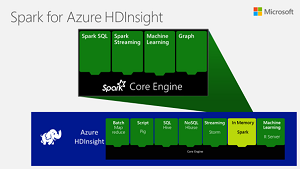 [Click on image for larger view.]
Spark on Azure HDInsight (source: Microsoft)
[Click on image for larger view.]
Spark on Azure HDInsight (source: Microsoft)
Microsoft reportedly worked with Hortonworks and Cloudera Inc. -- another Hadoop-based distribution vendor -- to contribute improvements to the technology, including and open source RESTful Web service for managing long-lasting Spark contexts and submitting Spark jobs. "This new capability was designed to make Spark a more robust back-end for running interactive notebooks and allow other applications to leverage Spark for their interactive workloads," Chiu said. "By ensuring high availability with Spark, we now offer the highest guarantee for Spark in the market with a 99.9 percent service level agreement."
Another enhancement of special interest to developers is deep integration with the IntelliJ IDE. "This allows developers to code with native authoring support for Scala and Java, local testing, remote debugging, and the ability to submit Spark applications to the Azure cloud," Chiu said.
Using the new service requires an Azure subscription or free trial. With that in hand, a getting started guide provides more info on using Spark with HDInsight.
MapR Enterprise-Grade Spark Distribution
MapR, a major distributor of Hadoop-based software with its "converged data platform," announced its new enterprise-grade Apache Spark distribution, which reportedly re-engineers the Spark stack for advanced analytics and combines it with MapR's own innovations and key, complementary open source projects.
"This new and unique Spark-focused offering redefines how companies leverage their Big Data," MapR said in a statement today. "From the deployment of real-time applications to the evolution of how those applications expand within an organization, the Spark-focused distribution for MapR can serve as a starting point to leverage the power of Spark as an essential component in a modern data architecture."
The new technology in the MapR Platform is now available in the company's Converged Community Edition and the Converged Enterprise Edition.
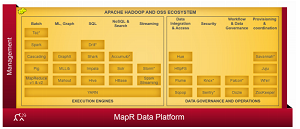 [Click on image for larger view.]
The MapR Data Platform (source: MapR Technologies)
[Click on image for larger view.]
The MapR Data Platform (source: MapR Technologies)
"The new distribution enables all advanced analytics including batch processing, machine learning, procedural SQL and graph computation," MapR said. "Because Spark runs seamlessly on MapR it benefits from the platform's patented enterprise-grade features such as Web-scale storage, high availability, mirroring, snapshots, NFS, integrated security, global namespace, etc. This native integration makes it the only reliable and production-ready platform for Spark workloads on-premise and in the cloud. Product extensions of the distribution could include real-time streaming and operational analytic capabilities, with MapR-Streams, MapR-DB and Hadoop as add-ons."
Couchbase Spark Connector
Couchbase Inc. today announced a Spark Connector for its NoSQL database.
"The Couchbase Spark Connector provides a flexible, efficient, open source integration between both of these best-of-breed technologies," the company said in a statement today. "The Couchbase Spark Connector enables ultra-fast streaming data exchange between the two platforms -- reducing time to insight and time to action. In short, Couchbase NoSQL database together with Apache Spark stream processing enables applications to get smarter, faster."
The company said example use cases for the connector include: real-time product recommendations; the detection of component failures, network intrusions and fraud; and a 360-degree view of products and customers.
Teradata Aster Connector for Spark
Big Data analytics and marketing company Teradata announced this new connector that provides integration with Spark and the company's Teradata Aster Analytics.
"The connector enables pre-built analytics functions from both solutions to be executed from Aster Analytics to form a truly multi-genre advanced analytics environment," the company said. "The result is that virtually anyone who can use Aster Analytics can also run advanced analytics on Spark without the need to learn or know Scala."
StreamAnalytix 2.0
Impetus Technologies is featuring StreamAnalytix 2.0 at the Spark Summit conference.
"StreamAnalytix 2.0 is the industry's first open-source based, enterprise-grade, multi-engine platform that empowers developers and data analysts to use drag-and-drop operators to rapidly and easily create real-time streaming analytics applications for any industry vertical, any data format and any use case," the company said. "With support for Apache Spark Streaming, in addition to Apache Storm, StreamAnalytix 2.0 is used by leading Fortune 1000 companies to process fast data for improved business outcomes. Overall, the platform has helped organizations in areas such as Internet of Things (IoT), sensor data analytics, e-Commerce and Internet advertising, security, fraud, insurance claim validation, credit-line management, call center analytics, business activity monitoring and log analytics."
Snowflake Data Source for Spark
Snowflake Computing announced Snowflake Data Source for Spark, yet another connector that joins the technology with the company's cloud-based data warehouse service.
"The new Snowflake Data Source for Spark, which is built on Spark's DataFrame API, provides developers a fully managed and governed warehouse platform for all their diverse data (such as JSON, Avro, CSV, XML, machine data, etc.) that offers a fast, higher level connection to data with Spark's API," the company said. "The results are increased developer productivity and a simple, agile, and easy-to-deploy platform that makes it significantly easier and faster to develop and execute successful Spark projects."
Stay tuned for more news about Spark from the Spark Summit, which runs through Wednesday.