News
Apache Kafka Stars in Two New Open Source Big Data Offerings
- By David Ramel
- May 25, 2016
Following the path of Hadoop and Spark, Apache Kafka is becoming a rising star in the Big Data ecosystem, playing a leading role in two brand-new open source offerings from LinkedIn, where Kafka originated, and Confluent, a company founded by former LinkedIn developers who helped create it.
According to its Web site, Kafka is "a high-throughput distributed messaging system" and is further described as "publish-subscribe messaging rethought as a distributed commit log."
While that doesn't tell you too much about how it's used in the real world, Confluent said its use cases range from collecting various kinds of data, such as user activity, logs, app metrics, stock ticker data and device instrumentation. "Its key strength is its ability to make high-volume data available as a real-time stream for consumption in systems with very different requirements -- from batch systems like Hadoop, to real-time systems that require low-latency access, to stream processing engines that transform the data streams as they arrive," Confluent said.
Apache Hadoop pioneer Raymie Stata said in a recent ADTmag interview that, "For applications that require the processing of streaming data, Kafka integrates very well with Hadoop and is becoming the tool of choice for capturing data streams."
Its GitHub site shows 3,142 stars, 1,914 forks, 183 contributors, 2,398 commits and 28 releases. Confluent said according to git log data, 112 people contributed to the new release, further backing up claims that Kafka is a growing, major player in the Big Data world.
Those claims are borne out from today's announcement that LinkedIn was open sourcing Kafka Monitor -- a framework for monitoring and testing Kafka deployments -- and yesterday's news from Confluent that its Confluent Platform was advanced to version 3.0 and Apache Kafka itself was moved to a 0.10 release.
 [Click on image for larger view.]
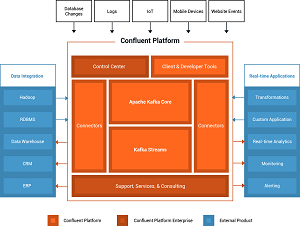
Confluent Platform 3.0 (source: Confluent)
[Click on image for larger view.]
Confluent Platform 3.0 (source: Confluent)
One new feature in the Confluent Platform 3.0 release is Confluent Control Center, a management and monitoring system similar to LinkedIn's Kafka Monitor. Confluent claimed its platform includes features and extensions added on to the Apache Kafka Core to simplify the configuration, deployment and management of Kafka.
Confluent said its Control Center, described as "the first commercial product through the Confluent Platform Enterprise offering," supports Kafka management and monitoring through a Web-based tool that provides connector configuration and end-to-end stream monitoring, from "producers" originating data streams to "consumers" performing analytics on the streamed data.
Another new feature in the platform, and Kafka 0.10 itself, is Kafka Streams, "a library that turns Apache Kafka into a full featured, modern stream processing system."
"Kafka Streams offers a true event-at-a-time processing model, handles out-of-order data, allows stateful and stateless processing and can easily be deployed on many different systems -- Kafka Streams applications can run on YARN, be deployed on Mesos, run in Docker containers, or just embedded into existing Java applications," Confluent said.
 [Click on image for larger view.]
The Kafka Monitor GUI (source: LinkedIn)
[Click on image for larger view.]
The Kafka Monitor GUI (source: LinkedIn)
Over at LinkedIn, Kafka Monitor is used heavily with a focus on testing.
"Kafka Monitor makes it easy to develop and execute long-running Kafka-specific system tests in real clusters and to monitor existing Kafka deployment's SLAs provided by users," LinkedIn said.
"Kafka Monitor is a framework to implement and execute long-running Kafka system tests in a real cluster," LinkedIn continued. "It complements Kafka's existing system tests by capturing potential bugs or regressions that are only likely to occur after prolonged period of time or with low probability. Moreover, it allows you to monitor Kafka cluster using end-to-end pipelines to obtain a number of derived vital stats such as end-to-end latency, service availability and message loss rate. You can easily deploy Kafka Monitor to test and monitor your Kafka cluster without requiring any change to your application."
The technical ins and outs of Kafka Monitor are explored in detail in a post published today by LinkedIn's Dong Lin on the company's engineering site.
"Apache Kafka has become a standard messaging system for large-scale, streaming data," Lin said. "In companies like LinkedIn, it is used as the backbone for various data pipelines and powers a variety of mission-critical services. It has become a core component of a company's infrastructure that should be extremely robust, fault-tolerant and performant."
He further discussed the product's testing capabilities.
"Developers can create new tests by composing reusable modules to emulate various scenarios (e.g. GC pauses, broker hard-kills, rolling bounces, disk failures, etc.) and collect metrics; users can run Kafka Monitor tests that execute these scenarios at a user-defined schedule on a test cluster or production cluster and validate that Kafka still functions as expected in these scenarios. Kafka Monitor is modeled as manager for a collection of tests and services in order to achieve these goals."
With the technology now open sourced, further work on the project, Lin said, will include adding additional testing scenarios, integrating it with Graphite and similar frameworks, and integrating it with fault injection frameworks, such as Simoorg, to allow for more failovers scenarios such as disk failures and data corruption.
Confluent is also looking ahead.
"In the forthcoming releases, the Apache Kafka community plans to focus on operational simplicity and stronger delivery guarantees," Confluent said. "This work includes improved data balancing, more security enhancements, and support for exactly-once delivery in Apache Kafka. Confluent Platform will have more clients, connectors and extended monitoring and management capabilities in the Control Center."
About the Author
David Ramel is an editor and writer at Converge 360.