News
SQL Strides in Open Source Big Data
- By David Ramel
- April 6, 2016
SQL continues to make inroads in the open source Big Data space this week, with Qubole Inc. open sourcing Quark for SQL virtualization, while MapR Technologies Inc. is converging SQL and JSON in the latest Apache Drill update.
The traditional RDBMS query language SQL was usurped in the fledgling NoSQL-dominated Big Data era but has continually gained acceptance as the related technologies have evolved and grown.
Quoble, a Big Data-as-a-Service (BDaaS) company, yesterday announced the open sourcing of Quark, a SQL optimizer that manages relationships among tables in an organization's databases, allowing for queries to span structured and unstructured data stores.
The Quark project now has an open source GitHub site led by Quoble, which features the technology in a Software-as-a-Service (SaaS) implementation in its Qubole Data Service (QDS). [Note: an earlier version of this story incorrectly said a version of the project was hosted by Cornell University. That is a separate project.]
"Quark models relationships between datasets using well-known database concepts like materialized views and OLAP cubes, enabling data analysts to automatically take advantage of the fastest and most efficient data set for their queries," Qubole said in a statement yesterday.
Distributed in a Java Database Connectivity (JDBC) jar package, it works with almost all JDBC-integrated tools, the company said.
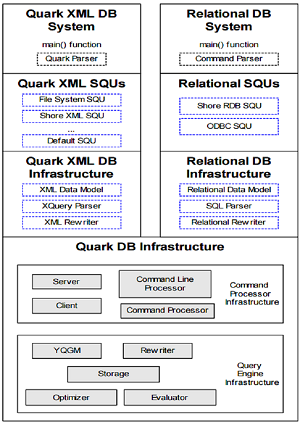 [Click on image for larger view.]
Cornell University's Quark Overview (source: Cornell University)
[Click on image for larger view.]
Cornell University's Quark Overview (source: Cornell University)
"We at Qubole are committed to the open source community," said CEO Ashish Thusoo. "With the open sourcing of Quark, we are offering a simple, optimized and compatible solution to allow developers to route SQL queries across data warehouses, Big Data SQL engines and data marts. Open source is core to our values at Qubole, and that's why we built our QDS platform to be agnostic and easily integrate with most open source data engine."
MapR, meanwhile, just today announced the latest edition of Apache Drill, version 1.6, is newly available "as the unified SQL layer" for its Converged Data Platform. It's described as a "schema-free SQL query engine for Hadoop, NoSQL and cloud storage." An open source project primarily driven by Hadoop distributor MapR and inspired by Google's Dremel project, it also has a GitHub site, where it's maintained by 58 contributors so far, speaking to its popularity.
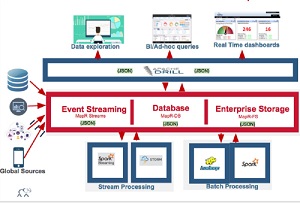 [Click on image for larger view.]
The MapR Converged Data Platform (source: MapR Technologies)
[Click on image for larger view.]
The MapR Converged Data Platform (source: MapR Technologies)
"Drill is used in a variety of use cases," MapR said. "For example, media companies can instantly query and analyze incoming content delivery network (CDN) files without requiring data transformations, allowing them to analyze several terabytes of CDN logs and reduce customer attrition. High-tech chip manufacturers can develop offerings that allow them to better analyze dropped calls and provide that information to their handheld device partners and thereby improve quality of service. Communications providers can instantly query and analyze logs from cell towers that enable mobile operators to proactively monitor and improve subscriber experience."
MapR said key features of Apache Drill 1.6 -- released three weeks ago -- include: flexible and operational analytics on JSON data residing in MapR-DB tables, via a document database plug-in; query planning improvements that boost performance of Hadoop and NoSQL queries; better memory management that lets users leverage larger and more SQL workloads on a MapR cluster; and improved integration with visualization tools such as Tableau.
"Apache Drill is a game changer for us," the company quoted customer Edmon Begoli at PYA Analytics as saying. "Most recently, we have been able to query, in under 60 seconds, two years worth of flat PSV files of claims, billing, and clinical data from commercial and government entities, such as the Centers for Medicaid and Medicare Services. Drill has allowed us to bypass the traditional approach of ETL and data warehousing, convert flat files into efficient formats such as Parquet for improved performance, and use plain SQL against very large volumes of files."
About the Author
David Ramel is an editor and writer at Converge 360.