Here's a round-up of this week's Big Data news from Looker, RethinkDB, Talend and others, featuring self-service data preparation, RethinkDB on Windows, Spark- and Presto-based BI, a turnkey data pipeline creator and more.
Dataiku yesterday announced a new edition of Data Science Studio (DSS), with UX and efficiency improvements to the data wrangling capabilities of the software suite for Big Data Analytics.
A key enhancement to DSS 2.3 is better data preparation features for both experienced and beginning Big Data analysts, the company said. DSS provides an integrated development platform designed to turn raw data into predictions for developers/analysts with differing skills and experience, with code editors to work with R, Python, Hive and others on a common platform that facilitates developer collaboration.
New in DSS 2.3, the company said, are data wrangling improvements such as the grouping of steps in complex preparation scripts and mass actions (deletions, grouping and so on) to boost visual data preparation. Global search for the DSS Data Catalog helps to find all instances of objects spread across several projects. New flow views capabilities adds additional "layers" into the data flow reportedly provides advanced productivity for large projects, the company said.
Other improvements include a refreshed SQL Notebook that lets users work with several queries within one notebook; tool tips to guide users through the UI with contextual help; and more. Dataiku last October added Apache Spark support to DSS.
- RethinkDB on Wednesday announced its namesake JSON "open source database for the real-time Web" is now available for Windows users as a Developer Preview.
Because Windows support was one of the most frequently requested items on the company's wish list for developers, the Mountain View, Calif., start-up launched a one-year porting effort described as an "intensive development, touching nearly every part of the database."
 [Click on image for larger view.]
Using RethinkDB in Visual Studio (source: RethinkDB)
[Click on image for larger view.]
Using RethinkDB in Visual Studio (source: RethinkDB)
"To try today's Developer Preview, simply download RethinkDB as an executable and run it on a Windows machine," said exec Ryan Paul in a blog post Wednesday. "We're making the preview available today so that our users can start exploring RethinkDB on Windows and help us test it in the real world. You shouldn't trust it with your data or use it in production environments yet. It's also not fully optimized, so you might not get the same performance that you would from a stable release."
Even with those caveats, the company invited developers to try out the database that sports a new approach different from those taken by NoSQL databases such as MongoDB. "RethinkDB is based on a fundamentally different architecture from MongoDB," the company says on its site. "Instead of polling for changes, the developer can tell RethinkDB to continuously push updated query results in real-time. You can also write applications on top of RethinkDB using traditional query-response paradigm, and subscribe to real-time feeds later as you start adding real-time functionality to your app."
-
BlueData Software Inc., which provides an infrastructure software platform for Big Data, on Wednesday announced Real-Time Pipeline Accelerator, a turnkey solution for creating real-time data pipelines.
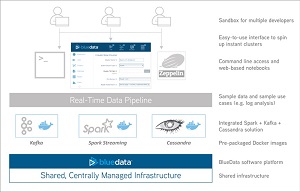 [Click on image for larger view.]
BlueData's Real-Time Data Pipeline (source: BlueData Software)
[Click on image for larger view.]
BlueData's Real-Time Data Pipeline (source: BlueData Software)
To do this, the new product relies on a trio of Big Data components: the aforementioned Spark Streaming for fast, in-memory, real-time analytics; Apache Kafka ("publish-subscribe messaging rethought as a distributed commit log") for capturing and publishing data streams; and Apache Cassandra, an open source distributed NoSQL database management system.
BlueData said its new product includes:
- Accelerated deployment for real-time data pipelines, with BlueData EPIC software and Docker containers.
- A ready-to-run Spark-Kafka-Cassandra lab for rapid prototyping, development, testing and quality assurance.
- Two sample end-to-end data pipelines integrated with Spark Streaming, Kafka and Cassandra as a starting point.
- Sample datasets and sample use cases for real-time streaming, with assistance from BlueData experts to help customers get started.
- Rapid prototyping and agile application development with the ability to spin up new clusters in a matter of minutes via self-service, with just a few mouse clicks.
- Improved developer productivity with Web-based Zeppelin notebooks that can be shared with other users in a multi-tenant environment on shared infrastructure.
Looker on Monday announced its namesake business intelligence (BI) platform now supports the Apache Presto distributed SQL query engine for Big Data analytics, along with Spark SQL, the module of the wildly popular Apache Spark open source project that specializes in fast, in-memory processing of streaming data for real-time analytics.
In addition to the brand-new support for Presto and Spark SQL, the Santa Cruz, Calif., company said its existing support for the Apache Impala (distributed SQL query engine for Apache Hadoop) and Apache Hive (Hadoop-based data warehouse infrastructure) projects has been updated. Also, it added to its list of supported data warehouses (Amazon Redshift) and ensured compatibility with the Amazon Elastic MapReduce (Amazon EMR) framework suite.
"Until today, it was painfully slow to do data analysis in Hadoop," the company said in a statement. "Typically, data analysts had to move subsets of data into data warehouses to perform analysis and, as a result, business teams rarely had direct access. Today, thanks to advances in the SQL query engines, Big Data technologies are finally accessible for business analytics and the vision of Hadoop as more than a data store is now a reality. Data analysts can now build a data model across all their data in Hadoop or other databases, easily transform raw data into meaningful metrics and allow business teams to utilize years of stored data in Hadoop."
-
Talend on Tuesday announced a new desktop app -- Talend Data Preparation -- for the self-service preparation of raw data for Big Data analytics further down the processing pipeline.
The company specializes in the integration of Big Data with graphical tools and wizards to generate native code to help developers work with technologies such as Hadoop, Spark, Spark Streaming and NoSQL databases.
The Redwood City, Calif., company said its new app simplifies and expedites data wrangling -- or data manipulation and analysis often done with spreadsheets -- an often difficult and time-consuming process.
"Available immediately as a free download, the open source desktop application allows users to explore, cleanse, enrich and combine data from different sources in minutes instead of hours using intuitive, drag-and-drop tools, smart guides and automated processing functions," the company said in a statement. "The result is that employees throughout an organization, from field marketing, to sales, operations to finance, can quickly and easily turn data into informed business actions."
A commercial version is planned for the second quarter of this year. "This self-service version will also offer data governance and compliance functionality and controls, the ability for multi-user role-based access, high performance server-based data processing capabilities and support for hundreds of data sources and targets," the company said.