News
Confluent Updates Open Source, Kafka-Based Platform for Big Data Streaming
- By David Ramel
- December 10, 2015
The Big Data streaming project Apache Kafka is all over the news lately, highlighted by Confluent Inc.'s new update of its Kafka-based Confluent Platform 2.0.
Wikibon analyst George Gilbert recently said Kafka "is becoming the de facto standard for Big Data ingestion." Last month saw the Apache open source project updated with a 0.9 release, and MapR Technologies Inc. just this week announced a MapR Streams system that some have characterized as a rival to the Apache project.
On the same day as the MapR announcement, Confluent, a startup founded by some of the original creators of the technology, announced the 2.0 release of its "Kafka-made-easy" platform, powered by Kafka 0.9 -- with a few extra enhancements added by the company itself.
Kafka, born at the business-oriented social site, LinkedIn, provides enterprises with easy access to real-time data streams to facilitate Big Data analytics. "With Kafka, developers can build a centralized data pipeline enabling microservices or enterprise data integration, such as high-capacity ingestion routes for Apache Hadoop or traditional data warehouses, or as a foundation for advanced stream processing using engines like Apache Spark, Storm or Samza," Confluent said. Besides LinkedIn, Kafka powers Big Data implementations at major companies such as Netflix, Uber, Cisco and Goldman Sachs.
According to the project's Wikipedia entry, "Apache Kafka is an open source message broker project developed by the Apache Software Foundation written in Scala. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds."
To that end, Confluent engineers have been enhancing the core technology and donating their contributions back to the open source community, including the extra goodies they tacked on to the new 0.9 release for packaging with the Confluent data platform. Those goodies include patches designed to increase performance, stability and security. Confluent also announced several other enhancements to its platform.
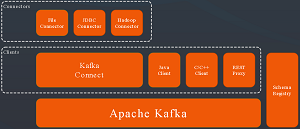 [Click on image for larger view.]
The Confluent Platform (source: Confluent)
[Click on image for larger view.]
The Confluent Platform (source: Confluent)
"In Confluent Platform 2.0 we've added new features to enable the operation of Apache Kafka as a centralized stream data platform," Confluent's Neha Narkhede said in a blog post Tuesday . "This entails adding the ability to operate multi-tenant Kafka clusters and enabling data flow from existing systems to Kafka. To enable multi-tenancy, this release adds security and user-defined quotas. To enable streaming data flow between existing data systems, this release adds Kafka Connect and better client support."
Kafka Connect helps developers -- without writing any code -- move data between the platform and other Big Data components, such as relational and NoSQL data stores, log files, application metrics data, Hadoop, data warehouses, search indexes and more, the company said. It features a JDBC Connector, for example, as well as one for the Hadoop Distributed File System (HDFS).
The new platform also includes more clients and improved existing clients. "Confluent Platform 2.0 includes fully featured native Java producer and consumer clients," Narkhede said. "It also includes fully supported, high performance C/C++ clients. These clients have feature and API parity with the Apache Kafka 0.9 Java clients and are also integrated with Confluent Platform's Schema Registry."
Other enhancements include data encryption to ensure safe data transport over the wire using SSL; authentication and authorization to allow access control with permissions that can be set on individual users or applications; and quality of service enabled by configurable quotas that allow throttling of reads and writes.
Confluent said those updates will improve performance and functionality at customer enterprises. Kafka is used at companies such as Microsoft, for example, where it handles more than 1 trillion messages each day while powering that company's Bing, Ads and Office operations, and LinkedIn, where more than 1.1 trillion messages are processed daily.
"Companies know how important stream processing is for their ability to create reactive customer environments -- and make their own business decisions moment to moment -- but it's a difficult thing to do," Confluent quoted Constellation Research analyst Doug Henschen as saying. "Kafka is becoming much more popular, as evidenced by the growing number of tools that are out there, and it anchors a stream processing ecosystem that is changing how businesses process data."
About the Author
David Ramel is an editor and writer at Converge 360.