News
Apache Advances Open Source Kylin for OLAP-on-Hadoop
- By David Ramel
- December 9, 2015
Just over a year after being open sourced by creator eBay Inc., the Kylin project -- a Big Data distributed analytics engine -- has been advanced by the Apache Software Foundation (ASF) to top-level status.
Apache Kylin is designed to provide a SQL interface and multi-dimensional analysis (OLAP) on Apache Hadoop, with support for extremely large datasets.
"A leading OLAP-on-Hadoop solution, Apache Kylin fills the gap between Big Data exploration and human use, enabling interactive analysis on massive datasets with sub-second latency for analysts, end users, developers and data enthusiasts," the ASF said in a statement yesterday. "With these capabilities, Apache Kylin brings back business intelligence (BI) to Apache Hadoop to unleash the value of Big Data."
When eBay open sourced its homegrown technology last year, the company said the technologies behind the Kylin approach aren't new, but rather leverage Hadoop's distributed computing model -- including the Hadoop Distributed File System (HDFS) -- and use it to improve on, for example, calculating and storing values from a large query for further use later.
The project's Web site says Kylin was designed to reduce Hadoop query latency for more than 10 billion rows of data, achieving sub-second latency on interactive queries that outperforms Apache Hive, a data warehousing infrastructure project that also features SQL functionality. Kylin currently integrates with other BI tools such as Tableau, with support for Microstrategy and Excel integration in the works.
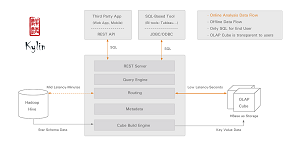 [Click on image for larger view.]
An overview of Kylin (source: eBay Inc.)
[Click on image for larger view.]
An overview of Kylin (source: eBay Inc.)
Kylin also is related to several other Apache projects. "We have tightly integrated Apache Calcite as our SQL Engine, and we provided Kylin Interpreter to Apache Zeppelin," said Luke Han, vice president of Apache Kylin. "Also, Kylin is big consumer of Hadoop, Spark, Kafka, HBase and Zookeeper, together with these other key members of the Big Data family, ASF is a natural home for Kylin."
eBay said the technology was developed in-house because company developers couldn't find any existing solutions to meet internal goals such as:
- Sub-second query latency on billions of rows.
- ANSI-standard SQL availability for those using SQL-compatible tools.
- Full OLAP capability to offer advanced functionality.
- Support for high cardinality and very large dimensions.
- High concurrency for thousands of users.
- Distributed and scale-out architecture for analysis in the terabyte to petabyte size range.
According to many user testimonials in the ASF news release, their goals have been well met.
"Apache Kylin and its low query latency with ANSI SQL on extreme datasets feature helped us to replace legacy RMDBs of JD.com's JCloud Open API platform, which eliminated the challenges of extreme data growth and smoothly expanding our capacity," said Ling Zhu, one such user at JD.com. "With insight on JOS API statistics data, growing by more than 700 million records every day, Apache Kylin enabled us to do multi-dimensional analysis on tens of billions of records with latency in seconds."
Apache Kylin software is released under the Apache License v2.0
About the Author
David Ramel is an editor and writer at Converge 360.