News
Spark Creator AMPLab Speeds Big Data Queries with Compressed Data Store
- By David Ramel
- November 12, 2015
AMPLab, the UC Berkeley research unit famous for creating the wildly popular Apache Spark technology, has now developed an adjunct open source project that uses data compression for faster queries.
The new technology is called Succinct, described as "a data store that enables efficient queries directly on a compressed representation of the input data." Basically, Succinct lets developers cram much more data into a given amount of memory through compression and then allows database queries to operate on that data without decompressing it or needing to scan the data. Not only does it result in faster queries, but those queries can be done on systems with much less RAM than is found in many Big Data implementations.
Succinct addresses the I/O bottleneck caused by huge amounts of data needing to be processed in systems where memory bandwidth and CPU performance are scaling up faster than the CPU-to-disk pipeline.
While other data compression techniques have evolved to address this I/O bottleneck, they don't fit all use cases, such as search and random access. With more such workloads evolving in modern Big Data practices, AMPLab researchers decided to tackle the problem, the project's Web site states, by addressing the question: "Is it possible to execute point queries (for example, search and random access) directly on compressed data without performing data scans?"
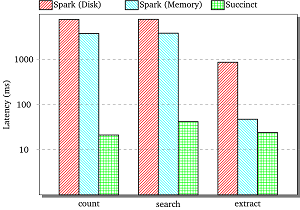 [Click on image for larger view.]
Speedier than Spark (source: AMPLab)
[Click on image for larger view.]
Speedier than Spark (source: AMPLab)
One result of the project, in the works for more than a year, was last week's release of Succinct Spark, a Spark package that facilitates random access and search, count and range queries on compressed Resilient Distributed Datasets (RDD).
"This release allows users to use Spark as a document store (with search on documents) similar to ElasticSearch, a key value interface (with search on values) similar to HyperDex, and an experimental DataFrame interface (with search along columns in a table)," said AMPLab's Rachit Agarwal in a blog post. "When used as a document store, Succinct Spark is 2.75x faster than ElasticSearch for search queries while requiring 2.5x lower storage, and over 75x faster than native Spark."
The Succinct site states that real-world benchmark tests demonstrate that Succinct performs sub-millisecond search queries on larger data stores held in faster storage compared to other systems that rely on indexing.
"For example, on a server with 128GB RAM, Succinct can push as much as 163GB to 250GB of raw data, depending on the dataset, while executing search queries within a millisecond," the site states.
Agarwal and UC Berkeley colleagues Anurag Khandelwal and Ion Stoica published a technical report that details the results of such benchmark tests. The researchers put Succinct up against the MongoDB and Cassandra NoSQL databases, HyperDex, a next-generation key-value and document store, and DB-X, an industrial columnar store that supports queries through the use of data scans.
"Evaluation on real-world datasets show that Succinct requires an order of magnitude lower memory than systems with similar functionality," the report states. "Succinct thus pushes more data in memory, and provides low query latency for a larger range of input sizes than existing systems."
The AMPLab researchers invited data developers to stay tuned for more developments related to the project, which is housed on the GitHub open source code repository.
"Over next couple of weeks, we will be providing much more information on Succinct -- the techniques, tradeoffs and benchmark results over several real-world applications," the project site states.
About the Author
David Ramel is an editor and writer at Converge 360.