News
MapR Releases Hadoop Distro with Apache Drill Update
- By David Ramel
- October 21, 2015
MapR Technologies Inc. today updated its enterprise Hadoop distribution with the latest open source Apache Drill technology.
The new Hadoop distro also includes a new Data Exploration Quick Start Solution said MapR, commonly characterized as one of the top three providers of enterprise Hadoop, along with Cloudera Inc. and Hortonworks Inc.
Apache Drill, an open source query engine for Hadoop that provides SQL-based interactive query functionality over a wide variety of NoSQL and relational data stores, was just last week updated to version 1.2, which is now included in the MapR software, adding to capabilities added in May with version 1.0.
Heading the improvements to Apache Drill 1.2 is relational database support. "Drill now includes a JDBC storage plugin for querying relational databases (RDBMSs)," project exec (and MapR engineer) Jacques Nadeau said last week. "Users can run SQL queries that join data between non-relational datastores (for example, MongoDB, HBase, HDFS, S3) and relational databases (for example, MySQL, Oracle). For example, a single query can join log files in HDFS with a users table in MySQL. Drill automatically pushes execution (projections, filters, partial joins, and so on) down into the RDBMS whenever possible." Nadeau and fellow MapR engineer Steven Phillips have taken lead roles on the Drill project.
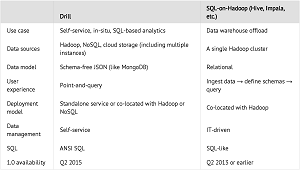 [Click on image for larger view.]
Drill vs. Traditional SQL-on-Hadoop Technologies (source: Apache Drill project)
[Click on image for larger view.]
Drill vs. Traditional SQL-on-Hadoop Technologies (source: Apache Drill project)
In announcing its updated Hadoop distribution, MapR said "Drill 1.2 continues to deliver on the promise of ANSI-SQL and help companies reuse existing investments in BI/analytic tools, with the addition of SQL-compliant analytical and window functions. New functions include Lead, Lag, First Value, and Last Value, in addition to the ranking and a variety of aggregated window functions delivered in Drill 1.1." MapR exec Neeraja Rentachintala today explored how to get started with the new ANSI SQL-compliant analytic and window functions in a blog post.
Along with the extended SQL analytics functionality, MapR said Drill 1.2 also features better performance and deeper integration with the Apache Hive project, which provides Hadoop-based data warehousing infrastructure. Performance improvements include a new metadata cache mechanism said to speed up queries against thousands of files, along with improved pushdown features for various data types to enable faster queries on the HBase and MapR-DB databases.
MapR's new Data Exploration Quick Start Solution targets organizations wanting to quickly deploy self-service Big Data analytics to reap the benefits of discovered business insights. Another new addition is an open sourced SQL test framework, which reportedly features more than 10,000 tests developed over several months.
"Releasing the test frameworks demonstrates our continued commitment in building a strong community to drive the innovation and quality of the Apache Drill OSS project," said Rentachintala. "Drill users are getting value from their relational structured data in Hadoop as well as enabling a broader set of users in an organization to leverage new types of semi-structured data sources such as JSON. As the only schema-free SQL engine for Big Data, Drill brings unprecedented flexibility and performance, rapid time to insights, granular security, scale in all dimensions and integration with existing tools."
About the Author
David Ramel is an editor and writer at Converge 360.