News
Spark Lighting a Big Data Fire, Survey Says
- By David Ramel
- September 24, 2015
Yeah, Spark is still hot.
It's seeing tremendous growth in contributing developers, user roles, applications, usage cases and just about every other Big Data metric you can think of, according to a new survey from commercial steward Databricks Inc., which says it's basically eating Hadoop's lunch.
Remember when Apache Hadoop, the originator of the whole Big Data movement, was all about Linux, NoSQL databases and alternative approaches to conventional data development?
If there's anything that speaks to Spark's mainstream ascension, it's a reported growth of 283 percent in Windows users from 2014 to 2015, with a 380 percent increase in SQL users. That means Windows users now account for 23 percent of all users, up from 6 percent last year, while SQL users now account for 24 percent of all users, up from 5 percent.
"Spark is quickly becoming the data processing platform that can be used by everyone -- not just data engineers," the survey stated. "The 2015 Spark Survey demonstrates increased Spark use by data scientists writing in Python, Windows users across both technical and business teams, and expert developers with real-time use cases, alongside expansion across new industries. Adoption of Spark has spread beyond the technology industry to help companies address a growing variety of data problems."
Databricks said its survey -- polling 1,417 respondents this summer -- cements Spark's claimed position as the most active Apache open source project in the Big Data space, with 600 contributors in the past year from more than 200 organizations. Development is led by Databricks, which was founded by the creators of the open source Spark project.
 [Click on image for larger view.]
Putting Spark to Use (source: Databricks)
[Click on image for larger view.]
Putting Spark to Use (source: Databricks)
Those contributors are primarily using Scala (reported in use by 71 percent of respondents, who could report using multiple languages), with Python being the second most reported programming language (58 percent) -- though it saw biggest growth, up from 39 percent last year -- followed by SQL (36 percent), Java (31 percent) and R (18 percent).
In fact, ease of programming was the second most reported "important aspect" of Spark (listed by 77 percent of respondents), behind performance (91 percent). Ease of deployment, advanced analytics and real-time streaming were also listed.
Based on the above and many more findings, Databricks claimed that "Spark is growing far beyond Hadoop," coinciding with other industry reports of how the real-time, streaming upstart is eclipsing its older big brother in the Big Data space.
"The rapid acceleration of Apache Spark adoption across new and diverse data problems is impressive," the survey stated. "The fact that this growth is propelling Spark beyond Hadoop is astounding. Spark isn't a quick and easy add on to an existing data technology stack; Spark is the focus of growing group of innovators that are driving tomorrow's data native culture."
Other key finding listed by Databricks include:
- The most common Spark deployments according to the community are: 48 percent standalone, 40 percent YARN within Hadoop and 11 percent Apache Mesos. Spark users who do not use any Hadoop components have more than doubled in 2015 (from 2014).
- Spark is being used for an increasingly diverse set of applications, particularly data scientists for machine learning, streaming and graph analysis use cases. In 2015, there are 56 percent more Spark streaming users than in 2014. The production use of advanced analytics, like MLib for machine learning and GraphX for graph processing, increased from 11 percent in 2014 to 15 percent in 2015. 75 percent of Spark users are also using two or more Spark components (51 percent of Spark users are using three or more Spark components).
- Spark is breaking down technology barriers between data scientists and engineers, who are working collaboratively to solve data problems. Of those surveyed, 41 percent identified themselves as Data Engineers, while 22 percent of respondents identified themselves as Data Scientists. Spark users are solving a variety of problems in different languages ... and all within the same framework.
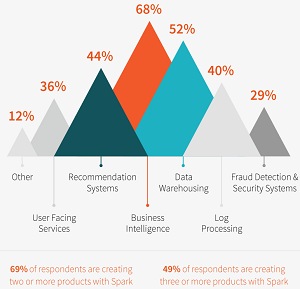
- Fifty two percent use Spark for data warehousing, 68 percent use it for business intelligence, 40 percent for processing application and system logs, 48 percent to build recommendation engines, 36 percent for user-facing services and 29 percent for fraud detection and security.
"The enthusiasm for Big Data is matched only by the pace of innovation," Databricks quoted analyst Nik Rouda of Enterprise Strategy Group as saying. "Many organizations are shifting to a 'Spark-first' strategy, recognizing its advantages of analytics versatility, development familiarity, superior performance, range of data sources supported and deployment flexibility. The market will no doubt continue to evolve, but Spark has established considerable momentum today."
Indeed, the market is evolving. As Spark has challenged and is reportedly eclipsing Hadoop, it's already under fire from competitors such as DataTorrent, which has pointed out perceived architectural weaknesses in Spark technology and has proffered its own product based on the open source Apex project as an enterprise alternative.
Sparks are flying in more ways than one.
About the Author
David Ramel is an editor and writer at Converge 360.