News
Google Big Data Beta Services Now Generally Available
- By David Ramel
- August 13, 2015
Two major Big Data components of the Google Cloud Platform have graduated from beta to general availability, the company said.
After moving to a beta program in April, the fully managed Cloud Dataflow service is available for batch and streaming processing of Big Data, along with the Cloud Pub/Sub data messaging service.
"Cloud Dataflow is specifically designed to remove the complexity of developing separate systems for batch and streaming data sources by providing a unified programming model," the company said in a blog post yesterday. "Based on more than a decade of Google innovation, including MapReduce, FlumeJava and Millwheel, Cloud Dataflow is built to free you from the operational overhead related to large scale cluster management and optimization."
The Dataflow service is aimed at data processing patterns such as Extract, Transform and Load (ETL), clickstream analysis and UI testing, facilitating both batch and stream-based continuous processing. "Dataflow provides programming primitives such as powerful windowing and correctness controls that can be applied across both batch and stream based data sources," the service's site says. "Dataflow effectively eliminates programming model switching cost between batch and continuous stream processing by enabling developers to express computational requirements regardless of data source."
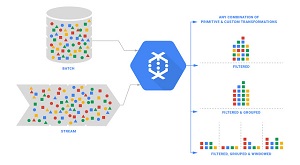 [Click on image for larger view.]
Dataflow Supports Batch and Stream Processing (source: Google)
[Click on image for larger view.]
Dataflow Supports Batch and Stream Processing (source: Google)
To that end, developers can use an open source Java SDK to integrate with other company solutions such as Cloud Storage, BigQuery and Cloud Pub/Sub.
The Cloud Pub/Sub service provides many-to-many, asynchronous messaging running on Google's cloud infrastructure, tying together disparate data-related services and systems. "Publish-and-subscribe messaging helps connect apps and devices that send data into processing pipelines, and back out to other apps, devices, and Google Cloud Platform services for further storage and analysis," the service's site states.
"Cloud Pub/Sub can help integrate applications and services reliably, as well as analyze big data streams in real-time," yesterday's blog post said. "Traditional approaches require separate queuing, notification, and logging systems, each with their own APIs and tradeoffs between durability, availability, and scalability."
About the Author
David Ramel is an editor and writer at Converge 360.