News
Teradata Backs Presto Big Data SQL Query Engine
- By David Ramel
- June 8, 2015
Teradata Corp., a Big Data analytics vendor, today announced it was throwing development resources at the open source Presto project, which provides a SQL query engine for interactive queries.
Created by Facebook in 2012, the tool is still in heavy use by the social media giant, running tens of thousands of queries a day on data stores scaling up to 300 PB. In addition to interactivity, another selling point of the open source technology is its ability to query different types of data wherever it resides, be it relational, NoSQL or in a proprietary format, stored on Hive or Cassandra or elsewhere.
Teradata, known for a variety of Big Data products and services, announced a multi-year commitment to contribute to the development of the open source project. As can be seen on the project's GitHub site, the project's main contributions have come from Facebook, which open sourced it in November 2013.
The fruits of phase one, to improve upon features that can simplify adoption of the technology, including installation, support documentation and basic monitoring, are already available for download at the Teradata site or on the project's GitHub site.
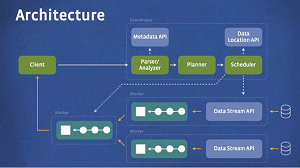 [Click on image for larger view.]
The Presto Architecture (source: Facebook)
[Click on image for larger view.]
The Presto Architecture (source: Facebook)
Coming later this year will be the benefits of phase two: "Integrate Presto with other key parts of the Big Data ecosystem, such as standard Hadoop distribution management tools, interoperability with YARN, and connectors that extend Presto's capabilities beyond the Hadoop distributed file system (HDFS)."
"We think we can make a big impact, because the gaps in Presto happen to be Teradata's strengths," company exec Justin Borgman said in a blog post today.
Borgman emphasized the ability of the tool to query disparate sources of information stored in the increasingly popular concept of data lakes. These typically are centralized data repositories stored on Hadoop that facilitate Big Data analytics. They can store data in HDFS and provide it to YARN-based tools such as Spark, Storm, Hive, HBase and so on.
"Presto is not merely SQL for Hadoop," Borgman said. "Presto is actually SQL for all the data platforms in your data lake. The list of platforms is ever-growing but already includes MySQL, Postgres, Kafka and Cassandra. This means that Presto allows querying data where it lives. A single query can combine data from multiple sources, allowing for analytics across your entire organization.
"Furthermore," Borgman continued, "because Presto runs on any distribution of Hadoop, users don't have to worry about being locked in to one Hadoop stack or another. If you build your SQL application on top of Presto, and later decide to switch to a different underlying distribution of Hadoop, no problem -- your work is now portable!"
 [Click on image for larger view.]
The Teradata Three-Year Roadmap for Presto Contributions (source: Teradata)
[Click on image for larger view.]
The Teradata Three-Year Roadmap for Presto Contributions (source: Teradata)
The Presto development expertise that Teradata is contributing to the project comes mainly in the form of engineers from Hadapt, a company headed by Borgman that was acquired last July. "Since that time, Hadapt has become the Teradata Center for Hadoop, responsible for the company’s portfolio of Hadoop-related products, including this major commitment to Presto," Borgman said. "In fact, 16 former Hadapters are now contributors to the Presto project, committing both their expertise and Hadapt intellectual property for the benefit of the open source community."
Those developers will now head the charge toward phase three, the goals of which include enabling Open Database Connectivity (ODBC) and Java Database Connectivity (JBDC) to ease enterprise adoption and improve integration with business intelligence (BI) tools. Security is also expected to be improved by limiting access based on job roles. These capabilities are expected next year.
Right now, developers can get their hands on Presto 101t from Teradata, a pre-tested, stable Presto release bundled into a pre-built RPM, or release package, or available in a self-contained sandbox virtual machine (VM). The sandboxes come with Cloudera Inc. and Hortonworks Inc. Hadoop distributions.
"Teradata's support of Presto is a very smart move," the company quoted analyst Robin Bloor of The Bloor Group as saying. "It legitimizes Presto and boosts the Hadoop ecosystem. It will improve the ability of organizations to gain business insight from Hadoop. I expect Presto to rapidly become a 'must have' component of the analytical ecosystems boosted by Teradata's commitment to open source development and commercial services."
About the Author
David Ramel is an editor and writer at Converge 360.