News
Microsoft Unveils New Big Data Products for the Azure Cloud
- By David Ramel
- April 30, 2015
During the opening keynote address of its Build developer conference, Microsoft unveiled a data warehouse for the Azure cloud, along with "elastic databases" and a data lake.
The new Azure SQL Data Warehouse preview announced yesterday was positioned as a counter to Amazon's Redshift.
Along with the new Azure Data Lake and "elastic databases" for Azure SQL Database, the warehouse offering further demonstrated the company's focus on helping customers implement and support a "data culture" in which analytics are used for everyday business decisions.
"The data announcements are interesting because they show an evolution of the SQL Server technology towards a cloud-first approach," IDC analyst Al Hilwa told this site. "A lot of these capabilities like elastic query are geared for cloud approaches, but Microsoft will differentiate from Amazon by also offering them for on-premises deployment. Other capabilities like Data Lake, elastic databases and Data Warehouse are focused on larger data sets that are typically born in the cloud. The volumes of data supported here builds on Microsoft's persistent investments in datacenters."
Azure SQL Data Warehouse will be available as a preview in June. It was designed to provide petabyte-scale data warehousing as a service that can elastically scale to suit business needs. In comparison, the Amazon Web Services Inc. (AWS) Redshift -- unveiled more than two years ago -- is described as "a fast, fully managed, petabyte-scale data warehouse solution that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools."
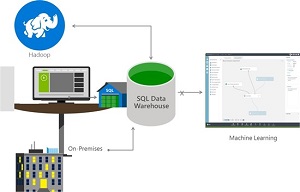 [Click on image for larger view.]
Introducing SQL Data Warehouse (source: Microsoft)
[Click on image for larger view.]
Introducing SQL Data Warehouse (source: Microsoft)
"There are other data warehouse offerings in the market today," said exec Scott Guthrie in the opening address, noting that AWS "has seen good uplift with its Redshift offering." Guthrie then said, "I want to spend a little time now talking about how Azure is even better" and put up a slide showing the advantages.
Guthrie went on to point out what he said are numerous advantages that Azure SQL Data Warehouse provides over AWS Redshift, such as the ability to independently adjust compute and storage, as opposed to Redshift's fixed compute/storage ratio. Concerning elasticity, Microsoft described its new service as "the industry’s first enterprise-class cloud data warehouse as a service that can grow, shrink and pause in seconds," while it could take hours or days to resize a Redshift service. Azure SQL Data Warehouse also comes with a hybrid configuration option for hosting in the Azure cloud or on-premises -- as opposed to cloud-only for Redshift -- and offers pause/resume functionality and compatibility with true SQL queries, the company said. Redshift has no support for indexes, SQL UDFs, stored procedures or constraints, Microsoft said.
Enterprises can use the new offering in conjunction with other Microsoft data tools such as PowerBI (data visualization), Azure Machine Learning (advanced analytics), Azure HDInsight (managed Apache Hadoop Big Data service) and Azure Data Factory (data orchestration).
"Azure SQL Data Warehouse is based on the massively parallel processing architecture currently available in both SQL Server and the Analytics Platform System appliance," said exec T.K. "Ranga" Rengarajan in a blog post yesterday.
Another new product, the Azure Data Lake repository for Big Data analytics project workloads, provides one system for storing structured or unstructured data in native formats. It follows the trend -- disparaged by some analysts -- pioneered by companies such as Pivotal Software Inc. and its Business Data Lake. It can work with the Hadoop Distributed File System (HDFS) so it can be integrated with a range of other tools in the Hadoop/Big Data ecosystem, including Microsoft's own Azure HDInsight and Azure Machine Learning.
"Azure Data Lake is built to solve for restrictions found in traditional analytics infrastructure and realize the idea of a 'data lake' -- a single place to store every type of data in its native format with no fixed limits on account size or file size, high throughput to increase analytic performance and native integration with the Hadoop ecosystem," Rengarajan said. "Azure Data Lake is a Hadoop File System compatible with HDFS that is integrated with Azure HDInsight and will be integrated with Microsoft offerings such as Revolution-R Enterprise and industry standard distributions like Hortonworks and Cloudera. The
preview for Azure Data Lake will be available later this calendar year."
For straight SQL-based analytics, Microsoft introduced the concept of elastic databases for Azure SQL Database, its cloud-based SQL Database-as-a-Service (DBaaS) offering. Azure SQL Database elastic databases reportedly provide one pool to help enterprises manage multiple databases and provision services as needed.
The elastic database pools let enterprises pay for all database usage at once and facilitate the running of centralized queries and reports across all data stores. The elastic databases support full-text search, column-level access rights and instant encryption of data. They "allow ISVs and software-as-a-service developers to pool capacity across thousands of databases, enabling them to benefit from efficient resource consumption and the best price and performance in the public cloud," Microsoft said in a news release.
Rengarajan expounded further. "Elastic databases -- available in preview today -- allow you to build [Software-as-a-Service] SaaS applications to manage large numbers of databases that have unpredictable resource demands," he said. "Managing dynamic resource needs can be more art than science, and with these new capabilities, you can pool resources across databases to support explosive growth and profitable business models. Instead of overprovisioning to accommodate peak demand, cloud ISVs and developers can use an elastic database pool to share resources across hundreds -- or thousands -- of databases within a budget that they control. Additionally, we are making tools available to help query and aggregate results across these databases as well as implement policies and perform transactions across the database pool."
About the Author
David Ramel is an editor and writer at Converge 360.