News
Apache Advances Parquet Columnar Storage Project
- By David Ramel
- April 28, 2015
Will Apache Parquet be the "next big thing" in the Big Data/Hadoop ecosystem? It was only 14 months ago that the Apache Spark project was graduated to a top-level project by Hadoop steward Apache Software Foundation (ASF), and that technology has quickly taken the industry by storm, rivaling Hadoop itself in publicity.
Now, 14 months later, comes news that the ASF has elevated Parquet to that status. While that specifically means "the project's community and products have been well-governed under the ASF's meritocratic process and principles," it can also serve as a springboard to more publicity, more use and more analytical power in the hands of enterprises.
As the ASF yesterday explained in a blog post:
Apache Parquet is an open source columnar storage format for the Apache Hadoop ecosystem, built to work across programming languages and much more:
- Processing frameworks (MapReduce, Apache Spark, Scalding, Cascading, Crunch and Kite).
- Data models (Apache Avro, Apache Thrift, Protocol Buffers and POJOs).
- Query engines (Apache Hive, Impala, HAWQ, Apache Drill, Apache Tajo, Apache Pig, Presto and Apache Spark SQL).
The project's Web site states the columnar format is available for use by any project in the Hadoop ecosystem, no matter the data processing framework, data model or language used for programming. That utility in some respects is similar to that of Spark, which has been characterized as a "Swiss Army Knife" for the Hadoop arena and is known for working with different components.
"Parquet is built to be used by anyone," the project site says. "The Hadoop ecosystem is rich with data processing frameworks, and we are not interested in playing favorites. We believe that an efficient, well-implemented columnar storage substrate should be useful to all frameworks without the cost of extensive and difficult to set up dependencies."
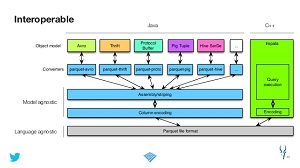 [Click on image for larger view.]
Apache Parquet (source: Apache Software Foundation)
[Click on image for larger view.]
Apache Parquet (source: Apache Software Foundation)
Developers at Twitter have been instrumental in contributing to the open source project, and chimed in on the news in the ASF blog post.
"At Twitter, Parquet has helped us scale our Big Data usage by in some cases reducing storage requirements by one-third on large datasets as well as scan and deserialization time," Twitter exec Chris Aniszczyk said. "This translated into hardware savings as well as reduced latency for accessing the data. Furthermore, Parquet being integrated with so many tools creates opportunities and flexibility regarding query engines. Finally, it's just fantastic to see it graduate to a top-level project and we look forward to further collaborating with the Apache Parquet community to continually improve performance."
Parquet has also been in use at other companies such as Cloudera, Netflix, Stripe and more.
"At Netflix, Parquet is the primary storage format for data warehousing," said Netflix engineer Daniel Weeks. "More than 7 petabytes of our 10-plus petabyte warehouse is Parquet0formatted data that we query across a wide range of tools including Apache Hive, Apache Pig, Apache Spark, PigPen, Prest, and native MapReduce. The performance benefit of columnar projection and statistics is a game changer for our Big Data platform."
The project originated in the fall of 2012 when Twitter and Cloudera combined their columnar format development efforts, resulting in a 1.0 release in July 2013. Less than a year later, having attained Apache incubator status, it was enjoying contributions from more than 40 developers.
Documentation on the latest bits can be found
here.
About the Author
David Ramel is an editor and writer at Converge 360.