News
Ryft Offers High-Speed Big Data in Proprietary Box
- By David Ramel
- March 13, 2015
Move over, Apache Spark and other Big Data speed kings, Ryft Systems Inc. is claiming to be the new top dog for fast analytics of huge amounts of data.
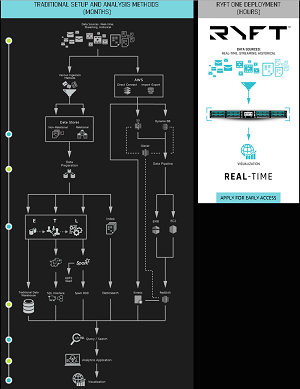
Ryft is eschewing common x86 cluster-based Big Data analytic approaches in favor of its Ryft ONE, a proprietary, small-footprint box combining new-age technologies and techniques designed for speed, and more speed.
How much speed? The company claims its Ryft Analytics Cortex (RAC) massively parallel hardware-accelerated solution can process historical and streaming data at more than 10 GB/sec. To help grasp that kind of analytical power, the company said: "A single Ryft ONE, using less power than a hair dryer, can store and analyze the equivalent of the contents of Wikipedia in 4.5 seconds, without any data indexing, preprocessing, tuning or partitioning." Wikipedia's English site alone is claimed to house more than 4.7 million articles.
With low power consumption and a single all-in-one 1U box replacing the numerous components found in many Big Data solutions, Ryft said its box attains processing speeds 200x faster than conventional hardware and reduces operational costs by 70 percent at the same time.
In fact, in its own benchmarking research, Ryft claimed to outperform Apache Spark, whose in-memory technology often places it near the top of such comparisons.
"Benchmark tests conducted in early 2015 against the highest-performing in-memory solutions showed that a single Ryft ONE outperformed large Spark clusters of 100 to 200 nodes, at a 70 percent operational savings," the company said. "Performance benchmarks for term frequency, exact search and fuzzy search are provided at ryft.com/products."
 [Click on image for larger view.]
Replacing Many Big Data Components with One (source: Ryft)
[Click on image for larger view.]
Replacing Many Big Data Components with One (source: Ryft)
Ryft combines the RAC massively parallel bitwise computing architecture -- which leverages field-programmable gate array (FPGA) chip technology -- a library of pre-built algorithm components, 48 TB of SDD storage, and a Ubuntu Linux server and x86-based chip for the front end interaction, along with many other components.
In a blog post yesterday, Ryft's Christian Shrauder went into more detail about FPGA technology and its benefits in certain situations, in reaction to a news article that brought up "some points around common misconceptions regarding FPGAs." While FPGA parallelism boosts some compute functions -- such as search -- and is the architecture for the future in certain applications, it can be difficult to work with, he said.
"It's just that they're not really used that intelligently at this point, and that is certainly true in the data analytics space," Shrauder said. "Making matters more interesting is that most people don't really understand how to use them or how to program them. That's where the genius of the Ryft ONE comes in: The Ryft ONE open API abstracts all that stuff away from the user, and makes it really simple to run macro data analytics.
"You just call simple functions in a language of your choice, so it's really no different than a C programmer today who might call qsort() to run a quick sort or bsearch() to run a binary search," he continued. "It's just that instead of that they are calling Ryft's open API functions to perform exact search, fuzzy search, generate term frequency documents, and so on."
Shrauder also went into more detail about the benchmarking tests comparing Ryft ONE to Spark and other solutions.
"The benchmark numbers that Ryft provides for exact search, fuzzy search and term frequency (which is the same thing as traditional word count for Spark/Hadoop) are amazing and something we're really proud of," he said. "10 GB/sec of analytics throughput for a fuzzy search, and 2.5 GB/sec for generating term frequency documents from arbitrary input? We couldn't be more thrilled with those stats!"
Shrauder cautioned that Ryft ONE isn't meant to be a replacment for Spark or Hadoop or any other solution, but is just another tool for the Big Data toolbox. "I can tell you this though -- if I do 10 GB/sec. of fuzzy search in a 1U platform, instead of requiring 3-4 fully loaded racks of servers running Spark, then I would absolutely use that 1U box for fuzzy search instead of that hundred-plus node Spark cluster," he said. "That not only makes good fiscal sense, but it means I can use that massive Spark cluster for other work."
The 15-year-old, Washington-based Ryft said its Big Data-in-a-box solution will be available early in the second quarter of this year (which means before mid-May), with an early-access program available. No pricing information was given.
About the Author
David Ramel is an editor and writer at Converge 360.