News
Hortonworks Crashes the Apache Spark Big Data Development Party
- By David Ramel
- September 25, 2014
Enterprise Hadoop vendor Hortonworks Inc., after several months of testing Apache Spark, yesterday announced it's investing more development resources into the open source technology in preparation for including it in the company's Big Data offerings later this year.
Spark, one of the most active projects under the Apache Software Foundation (ASF), is a cluster-based data analytics framework with in-memory capabilities that improves on the traditional batch-oriented MapReduce programming paradigm for general analytics and also offers the ability to include new workloads such as streaming, interactive queries and machine learning.
Hortonworks in May announced it was including Spark as a tech preview component of its Hortonworks Data Platform 2.1 (HDP). Based on that preview, the company apparently decided it wasn't ready for enterprise prime-time and needs development work to be included in HDP, a Hadoop-based distribution bundled with services and support targeting enterprise use.
"Based on experiences we've gathered over the past few months, we have outlined a set of initiatives to address some of the current challenges with the technology that will make it easier for users to consume as part of the completely open source HDP," Hortonworks announced yesterday in a blog post. The company said it plans to include Spark support in its Enterprise Plus Support Subscription later this year.
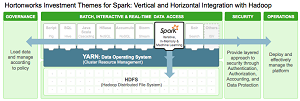 [Click on image for larger view.]
Integrating Spark with Hadoop (source: Hortonworks)
[Click on image for larger view.]
Integrating Spark with Hadoop (source: Hortonworks)
"There has been unbridled excitement for Spark over the past few months because it provides an elegant, attractive development API and allows data workers to rapidly iterate over data via machine learning and other data science techniques," Hortonworks said.
Until now, Databricks Inc. has been the primary developer of the Spark project. Databricks is a San Francisco startup founded last year by members of the team that originally created the technology at the University of California, Berkeley, AMPLab.
While the project enjoys tremendous, widespread development support from more than 200 contributors coming from more than 50 organizations, Databricks and UC Berkeley developers have taken the lead. Developers from those two organizations comprise more than half of the project's 32 "committers," or high-level programmers with the authority to commit changes to the project source code. Databricks supplies the most committers, 10, and company employee Matei Zaharia has supplied the most individual contributions of the development community.
No Hortonworks employees are listed as committers.
The Spark stack is the core of the Databricks Cloud project, currently in beta, which was announced June 30.
The next day, Databricks announced a partnership to improve the Spark technology with Hadoop vendors Cloudera Inc. and MapR Technologies Inc. -- often characterized as two of the top three Hadoop distribution vendors along with competitor Hortonworks -- as well as with Intel Corp. and IBM Corp. The companies said they were "joining efforts to broaden support for Apache Spark, while simultaneously standardizing it as the framework of choice by bringing popular tools from the MapReduce world to this new engine." Cloudera and MapR had previously incorporated Spark support in their distributions.
Hortonworks yesterday said its increased development participation will focus on two areas, one of them being the standard "table stakes" concerns of governance, security and operations.
The other is deeper integration of Spark with YARN, yet another resource negotiator that improves upon the MapReduce model and simplifies Big Data analytics with other types of workload engines.
"Apache Spark currently scales to meet the needs of just a handful of concurrent users and is typically stretched to its limits with larger clusters," Hortonworks says on its Web site. "We also advise customers to consider having multiple deployments (that is, a handful of users on a single Spark instance which is convenient via YARN).
"There has been a number of proposed workloads and use cases for Spark," Hortonworks continued, "but thus far, we have only seen clear benefits around machine learning and iterative workloads."
Yesterday, in announcing its increased participation in the project, Hortonworks said, "Deeper integration of Spark with YARN will allow it to become a more efficient tenant alongside other engines, such as Hive, Storm, HBase and others, simultaneously, all on a single data platform. This avoids the need to create and manage dedicated Spark clusters to support that subset of applications for which Spark is ideally suited and more effectively share resources within a single cluster."
Along with governance, security and operations improvements, Hortonworks outlined two other immediate goals in phase one of its initiative, described as "laying the groundwork."
The first goal is improved integration with Apache Hive data warehousing software.
The second goal is support for the Optimized Row Columnar (ORC) file format, which was introduced by the Hive community and is becoming the de facto standard for Hive, Hortonworks said. The company said those two improvements will be enacted this week, while the remaining first-phase goals of security and operations enhancements are expected by year's end.
Phase two will focus on optimizing Spark for YARN, advanced security and an easier debugging process. The YARN optimization will focus on improved reliability and scale.
Hortonworks said many of the phase one improvements are currently realized in its HDP Tech Preview, with the rest coming later this year, followed by phase two enhancements expected early next year.
"As is the case with many emerging technologies, Spark has a significant road ahead of it in order to make it ready for the enterprise," Hortonworks says on its Web site. "Hortonworks will work within the open community to represent the needs of the modern enterprise in the ASF and help push this project forward."
Databricks today welcomed the move by Hortonworks.
"While Databricks was founded by the creators of Spark and continues to be the driving force behind it, one of the critical factors in the success of Spark has been the large developer community contributing to it (it's the most active Big Data project with over 300 contributors in the last 12 months alone)," Databricks spokesman Arsalan Tavakoli told this site. "In this sense, we're very excited to have Hortonworks join this community and contribute their expertise -- improved YARN support, ORC support, and compatibility with Hive releases are all things that the Spark user community will welcome.
"Also, this is just another testament to the growth in Spark," Tavakoli continued. "You now have 10-plus distributors of Spark -- including all the major Hadoop distributors, and making significant investments around it. This is partially because of all the capabilities and benefits of Spark, but is in large part also to the significant demand coming from existing and potential customers who are already using Spark and demanding support from their vendors."
About the Author
David Ramel is an editor and writer at Converge 360.