News
Oracle Adds SQL Twist to Big Data
- By David Ramel
- July 15, 2014
In an age of NoSQL and Hadoop, original "Big 3" RDBMS vendor Oracle Corp. is getting back to its roots with a new product designed to integrate access across all three data stores with a single SQL query.
Oracle Big Data SQL is designed to eliminate problems with data silos, or isolated data stores that can't exchange content with other data sources and aren't integrated with an organization's overall data administration, hindering widespread and comprehensive analytics.
"The offering allows customers to run one SQL query across Hadoop, NoSQL and Oracle Database, minimizing data movement while increasing performance and virtually eliminating data silos," the company said in a statement. "Oracle Big Data SQL enables customers to gain a competitive advantage by making it easier to uncover insights faster, while protecting data security and enforcing governance. Furthermore, this approach enables organizations to leverage existing SQL investments in both people skills and applications."
Oracle Big Data SQL runs on the company's Big Data Appliance and can work with its Exadata Database Machine (a platform running the company's RDBMS flagship database), using that product's "Smart Scan" technology that optimizes targeted query results.
 [Click on image for larger view.]
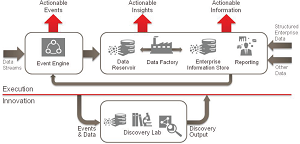
The Oracle Vision of Big Data Information Architecture
[Click on image for larger view.]
The Oracle Vision of Big Data Information Architecture
(source: Oracle Corp.)
The Oracle Big Data Appliance is an engineered, pre-integrated, full-rack setup centered on multiple Sun servers, coming with the Oracle NoSQL database and Cloudera Hadoop distribution and associated software.
SQL-based querying across all kinds of structured and unstructured data reduces data movement, the company said, greatly speeding up the analysis of these disparate data sources. "Organizations no longer have to copy and move data between platforms, analyze with a MapReduce-powered language, or construct separate queries for each platform and then figure out how to connect the results," Oracle said.
The new offering comes with software for security-related functionality such as data encryption, authentication, authorization and auditing.
The product is the latest in a bevy of products bringing SQL functionality to Hadoop-based Big Data implementations, making them more accessible and overcoming some of the limitations of the original Hadoop/NoSQL/MapReduce ecosystem. One advantage of using SQL, Oracle said, is that its declarative, data-oriented nature lets users describe the shape of query results, without having to wrestle with complex data access details or processing. In this Big Data/SQL arena are Apache Hive, Hadapt, HP Vertica, Splice Machine, Shark, Pivotal HAWQ and many others.
One of those others is Impala from Oracle partner Cloudera Inc., a massively parallel processing SQL query engine running natively in Apache Hadoop.
"When it comes to querying data in Hadoop, we've seen overwhelming demand from customers for SQL," said Mike Olson, Cloudera founder, chief strategy officer and chairman of the board. "This is why Cloudera has developed Impala -- which Oracle includes on Oracle Big Data Appliance -- to enable customers to query data with SQL natively and efficiently in Hadoop.
"For customers who need to query and analyze data residing in both Hadoop and Oracle Database, Oracle Big Data SQL offers support for HDFS, preserves their existing SQL skills and security policies, and makes it easier to integrate Hadoop with their existing Oracle infrastructure."
The new offering will be available in the third quarter of this year.
About the Author
David Ramel is an editor and writer at Converge 360.