News
GraphLab Makes Big Data Machine Learning More Accessible
- By David Ramel
- July 15, 2014
Seattle-based start-up GraphLab Inc. today emerged from stealth mode with a new platform designed to make large-scale machine learning more accessible to data scientists and developers everywhere.
GraphLab Create 1.0, to be officially unveiled at the company's conference in San Francisco next week, promises to be 100 to 10,000 times faster at analytics operations and model training than industry alternatives, company exec Johnnie Konstantas said in an e-mail to this site. She said the company benchmarked the new offering against products such as MLlib (part of the Apache Spark project), Sci-Kit Learn and Mahout.
With the much-publicized drought of available data scientists and experienced Big Data developers, the company seeks to provide Big Data analytics capabilities -- such as used in recommendation systems -- to companies of all sizes.
"Today, there is a shortage of data scientists," the company said in a statement. "Deriving value from a company's data requires these experts to integrate a range of highly complicated, disparate tools and datasets. GraphLab Create provides enterprise-grade machine learning that brings together the ease of use and computing scale that make it possible for one data scientist to do the job of many."
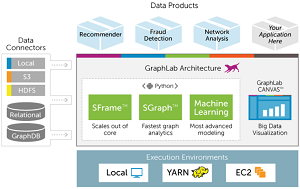 [Click on image for larger view.]
GraphLab 1.0 architecture
[Click on image for larger view.]
GraphLab 1.0 architecture
(source: GraphLab Inc.)
GraphLab technology was born out of research work conducted at Carnegie Mellon University by Carlos Guestrin, PhD., in 2009. It was originally intended for graph analysis. Functionality to process tables and text was added, and CEO Guestrin formed the company to improve upon the work of the GraphLab open source project and provide a commercial offering.
The company said the beta software has been in use in major companies since March to make recommendations, detect fraud, analyze text and sentiment, score marketing content and perform other analytics.
Konstantas said the new product serve the needs of data scientists and Big Data developers alike. "Companies that want to take advantage of predictive analytics need two sets of expertise: data science for machine learning and developers to code the prototypes of scientists into products that can scale," she said. "The GraphLab Create platform gives each the tools of the other. Data scientists can get to production code without needing to be programmers and developers get machine learning know-how in a platform that makes it easy to learn machine learning."
GraphLab said developers can save weeks or months of time by prototyping on a single machine and moving a project to production with the same code, sparing the need to re-code the prototype project.
"GraphLab Create lets developers be productive with predictive analytics the way a PhD. in statistical machine learning might," Konstantas said. "They can provide their companies with products for data-driven decision making."
The platform features Hadoop integration so developers can easily use data stored on the Hadoop Distributed File System (HDFS). It has been certified by major Hadoop vendor Cloudera and is available as a component of the Pivotal HD Hadoop distribution platform.
While C++ was used to write the core of the platform, it's accessible via a Python API. It uses the SFrame and SGraph scalable data structures and can process data in any form from any location, including local data stores or common stores such as the Amazon Web Services (AWS) EC2 cloud. It runs on Mac OS X 10.8 or later and several versions of popular Linux distributions, including Ubuntu, Debian, Red Hat Enterprise Linux and SUSE Enterprise Linux Server. Windows support is planned.
Konstantas said GraphLab 1.0 is free to download and try without any time restrictions, while future releases will be bundled with additional features for products with multiple tiers of capabilities and pricing.
With the release of the initial version, Konstantas said the company's developers were now working on those additional capabilities. "We are focused on furthering scale on distributed compute and adding features for more automation, such as machine learning model auto tuning and ease of use," she said.
About the Author
David Ramel is an editor and writer at Converge 360.