News
Splice Machine's 'Only Hadoop RDBMS' Released as Beta
- By David Ramel
- May 12, 2014
Splice Machine Inc. today announced the public beta of what it claims to be "the only Hadoop RDBMS" on the market, capable of supporting real-time applications while natively supporting Apache Hadoop.
It's the latest Big Data product seeking to make original, batch-oriented Hadoop-based solutions more performant and accessible to mainstream relational database management systems (RDBMS) developers.
The Splice Machine "next-generation database platform" combines the scale-out technology of Hadoop with the advantages of traditional RDBMSes, such as the familiar ANSI SQL query language and the bedrock RDBMS transaction properties of atomicity, consistency, isolation and durability (ACID). At the same time, it leverages the distributed, real-time computing ability of HBase, the key/value data store built on Hadoop.
"Splice Machine marries two proven technology stacks to create its Hadoop RDBMS: Apache Derby and Apache HBase/Hadoop," the company said in a statement. "We replaced the storage engine in Apache Derby with HBase and redesigned the planner, optimize, and executor to leverage the distributed HBase computation engine. This enables Splice Machine to achieve massive parallelization by pushing the computation down to each distributed HBase server."
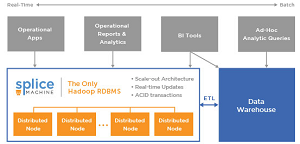 [Click on image for larger view.]
The Splice Machine solution (source: Splice Machine Inc.)
[Click on image for larger view.]
The Splice Machine solution (source: Splice Machine Inc.)
Wikipedia describes the Derby database engine as "a full-functioned relational embedded database-engine, supporting JDBC and SQL as programming APIs" that uses IBM DB2 SQL syntax. HBase is described as a non-relational, distributed database running on the Hadoop Distributed File System (HDFS) with features such as compression and in-memory operation.
While a plethora of products claim some kind of SQL/RDBMS-plus-Hadoop capabilities of varying kinds and degrees, Splice Machine claims they all have disadvantages.
SQL-on-Hadoop solutions such as Apache Hive and Cloudera Impala are analytics-only, with no real-time updates or transactions and limited SQL compatibility, it said.
Traditional RDBMSes such as Oracle, IBM DB2 and Microsoft SQL Server incur a high cost to scale up, the company said, and some require application rewrites for manual sharding, or horizontal partitioning. They can't take advantage of Hadoop's distributed computing infrastructure and present a "maintenance nightmare to prune data from overwhelmed databases."
NoSQL databases such as Cassandra and MongoDB emerged as the answer to scalability problems, but have limited SQL language support, can't do transactions, joins or secondary indices and require expensive efforts to recreate database functionality in individual applications.
"As the only Hadoop RDBMS, Splice Machine delivers the best of all worlds -- the ease of data access through SQL, the reliability of real-time updates of ACID transactions, and a 10x price/performance improvement over traditional RDBMSs using parallelized scale-out technology," CEO
Monte Zweben told this site. "Consider Splice Machine if you have an existing RDBMS experiencing cost/scaling issues or if you want to get robust SQL access (including supporting real-time applications) to your Hadoop data."
Splice Machine makes no secret of the target market for its new product, as its Web site states: "Replace your Oracle and MySQL databases with the scale-out Hadoop RDBMS."
The San Francisco-based company, recently named by research company Gartner as a "cool vendor," said it already has 15 charter customers in a range of industries. It said Harte Hanks, a marketing service company, saw price/performance benefits of 10x compared with their existing Oracle RAC databases.
Another customer, Robin Bloor, chief analyst and co-founder of The Bloor Group, said in a statement, "For developers and database architects looking for better ways to build applications, Splice Machine's approach offers a unique combination of benefits. By combining transactional integrity and ANSI SQL support with the horizontal scale-out of Hadoop, Splice Machine is disrupting the traditional RDBMS market, and helping to make Big Data a reality for real-time applications."
Zweben noted that no longer is Hadoop just for batch analytics, as developers can now support real-time applications and operational analytics. "No longer must database developers worry about database scalability," he told this site. "They can even store historical data with operational data and use them together to drive real-time actions (for example, real-time personalization or system telemetry). They can also continue to use their BI and SQL tools and applications without the rewrites necessary for other scale-out technology such as NoSQL databases."
The beta database is available for download.
About the Author
David Ramel is an editor and writer at Converge 360.