News
Code Quality Research: Functional Languages Beat Procedural/Object-Oriented
- By David Ramel
- October 3, 2017
Academic researchers have published a study investigating the effect of programming languages on software quality, concluding the issue is hard to quantify but also identifying significant findings, such as functional languages having an edge over procedural/object-oriented languages.
The research -- "A Large-Scale Study of Programming Languages and Code Quality in GitHub" -- was just published in the October edition of Communications of the ACM (Association for Computing Machinery) by academicians at the University of Virginia and University of California, Davis.
In attempting to gauge how code quality is influenced by the type of programming language used, the researchers analyzed more than 700 GitHub projects containing some 63 million lines of source code. They concluded the question is quite complicated, influenced by many interacting factors, and difficult to empirically evaluate.
Nevertheless, they identified several "significant" effects (at least statistically) that they in turn characterized as "small" or "modest," implying other factors may be more important.
"By triangulating findings from different methods, and controlling for confounding effects such as team size, project size, and project history, we report that language design does have a significant, but modest effect on software quality," the paper states.
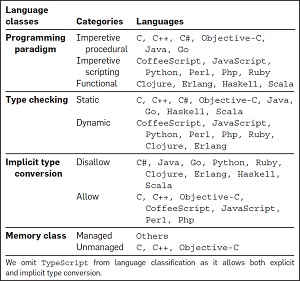 [Click on image for larger view.]
Categorizing Programming Languages (source: ACM)
[Click on image for larger view.]
Categorizing Programming Languages (source: ACM)
Here are some related statements on that issue, culled from the report (noting that the researchers lumped object-oriented languages among procedural languages):
- It does appear that disallowing type confusion is modestly better than allowing it.
- Among functional languages, static typing is also somewhat better than dynamic typing.
- Functional languages are somewhat better than procedural and scripting languages, being associated with fewer defects.
- Managed memory usage is better than unmanaged.
- The defect proneness of languages in general is not associated with software domains.
- Languages are more related to individual bug categories than bugs overall.
Even in the face of these observations, the researchers provided caveats about reaching any definitive conclusions based on the research.
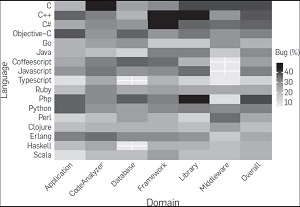 [Click on image for larger view.]
Interaction of language's defect proneness with domain. Each cell in the heat map represents defect proneness of a language (row header) for a given domain (column header). The "Overall" column represents defect proneness of a language over all the domains. The cells with white cross mark indicate null value, that is, no commits were made corresponding to that cell. (source: ACM)
[Click on image for larger view.]
Interaction of language's defect proneness with domain. Each cell in the heat map represents defect proneness of a language (row header) for a given domain (column header). The "Overall" column represents defect proneness of a language over all the domains. The cells with white cross mark indicate null value, that is, no commits were made corresponding to that cell. (source: ACM)
"It is worth noting that these modest effects arising from language design are overwhelmingly dominated by the process factors such as project size, team size, and commit size," the paper said. "However, we caution the reader that even these modest effects might quite possibly be due to other, intangible process factors, for example, the preference of certain personality types for functional, static languages that disallow type confusion."
And the paper's conclusion states, in part: "Even large datasets become small and insufficient when they are sliced and diced many ways simultaneously. Consequently, with an increasing number of dependent variables it is difficult to answer questions about a specific variable's effect, especially where variable interactions exist. Hence, we are unable to quantify the specific effects of language type on usage. Additional methods such as surveys could be helpful here. Addressing these challenges remains for future work."
The paper was authored by Baishakhi Ray, University of Virginia; and Daryl Posnett, Premkumar Devanbu and Vladimir Filkov, all at the University of California, Davis.
About the Author
David Ramel is an editor and writer at Converge 360.