News
LinkedIn Open Sources Cruise Control for Kafka Automation
- By David Ramel
- August 28, 2017
Apache Kafka, a popular Big Data component for distributed data streaming, is getting an automation boost from a new open source offering from LinkedIn called Cruise Control.
Kafka is used to stream data in real-time just like messages are streamed in a publish-and-subscribe system. It can, for example, be used to capture streams of data emanating from network-connected systems or sensors and pipe them into an enterprise Hadoop implementation for processing.
While it has grown in popularity, LinkedIn pointed out some shortcomings with the technology that it has addressed in-house with Cruise Control, now donated to the community and available on GitHub.
"While Kafka has proven to be very stable, there are still operational challenges when running Kafka at such a scale," LinkedIn's Jiangjie Qin said in a blog post today. "Brokers fail on a daily basis, which results in unbalanced workloads on our clusters. As a result, SREs expend significant time and effort to reassign partitions in order to restore balance to Kafka clusters."
Thus Cruise Control was developed -- sparked by an intern, Efe Gencer -- to supply intelligent automation to deal with such issues. It tracks workload performance on clusters to ensure user-defined goals are met, adjusting administrative resources on the fly to keep the goals on track.
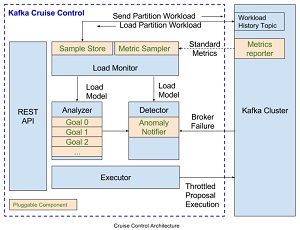 [Click on image for larger view.]
Cruise Control (source: LinkedIn)
[Click on image for larger view.]
Cruise Control (source: LinkedIn)
The project had goals of its own, designed to provide reliable automation, be resource efficient, be extensible, and be "a general framework that could understand the application and migrate only a partial state and be used in any stateful distributed system."
LinkedIn's own in-house goals included:
- Kafka clusters must be continually balanced with respect to disk, network, and CPU utilization.
- When a broker fails, we need to automatically reassign replicas that were on that broker to other brokers in the cluster and restore the original replication factor.
- We need to be able to identify the topic-partitions that consume the most resources in the cluster.
- We need to support low-touch cluster expansions and broker de-commissions. These operations are otherwise arduous, due to the need to manually reassign partitions after adding or removing a broker from a cluster.
- It is useful to be able to run clusters with heterogeneous hardware (e.g., to quickly remediate hardware failures when there is a shortage of identical hardware). However, heterogeneity compounds operational overhead, since SREs need to be minutely aware of hardware differences when balancing such clusters. Cruise Control should be able to support heterogeneous Kafka clusters and multiple brokers per machine.
The tool provides a REST API for user interaction with components such as a load monitor, anomaly detector and analyzer, or "brain" for Cruise Control.
Qin said future work on the project is planned to include: more cluster optimization goals; integration with cloud management systems (CMSs); provide operational insights for help in activities such as capacity planning and performance tuning; and generalization.
Speaking of the latter, Qin said: "We developed Cruise Control with the realization that a dynamic load balancer is a useful facility for any distributed system. Cruise Control's components for metric aggregation, resource utilization analysis, and the generation of optimization proposals are equally applicable to other distributed systems as well.
"We want to abstract those core components in the long term and make them available to other projects as well. Our vision for Cruise Control is to build it in a manner that allows for straightforward integration with any distributed system to facilitate application-specific performance analysis, optimization, and execution."
About the Author
David Ramel is an editor and writer at Converge 360.