News
Apache Kafka Grabs Big Data Spotlight
- By David Ramel
- September 28, 2016
After Apache Hadoop got the whole Big Data thing started, Apache Spark emerged as the new darling of the ecosystem, becoming one of the most active open source projects in the world by improving upon certain aspects of Hadoop. Now, Apache Kafka is increasingly generating buzz in the industry with a Spark-like climb into the Big Data spotlight.
Just today, for example, with the Strata + Hadoop World conference underway in New York, Kafka was the focal point of announcements from Confluent Inc. and Heroku Inc.
Kafka, as explained on the official Web site for the open source technology, is "a high-throughput distributed messaging system," or, in other words, a "publish-subscribe messaging rethought as a distributed commit log." It's used to manage data streams for Big Data analytics, often in conjunction with other projects like Apache Storm. Kafka, for example, can be used to capture streams of data emanating from network-connected systems or sensors and pipe them into an enterprise Hadoop implementation for processing.
On the project's GitHub site, Kafka boasts 228 contributors, 3,833 stars, 2,741 commits, 32 releases and 2,379 forks.
That activity speaks to its increasing prominence at conferences like this week's New York show. Here's a rundown of today's announcements.
'Introducing Apache Kafka for the Enterprise'
Confluent, founded by the people who built the technology while at LinkedIn, provides a platform used by organizations to access data as real-time streams.
The company today announced enhancements to its Confluent Platform 3.0, which was announced in May.
"I'm delighted to share the details of our extensions to Confluent Enterprise that are needed to simplify running Kafka in production at scale," said exec Neha Narkhede in a blog post.
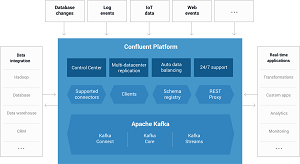 [Click on image for larger view.]
The Upcoming Confluent 3.1 Platform (source: Confluent)
[Click on image for larger view.]
The Upcoming Confluent 3.1 Platform (source: Confluent)
Those extensions include multi-datacenter replication and auto data balancing.
The highly available multi-datacenter streaming capability targets organizations with mulitple datacenters in disparate locations. For Big Data analytics, that data needs to be synchronized, and organizations need to make sure it complies with compliance and security policies.
"There is widespread demand for running Kafka to enable multi-datacenter streaming," Narkhede said, mentioning two approaches to do so. The Confluent platform was enhanced with functionality that facilitates the replication of streams of events from spread-out datacenters and combines them into one central location for easier analytics.
Automatic data balancing, meanwhile, "is a long-awaited feature useful for operating Apache Kafka in production," Narkhede said. "When executed, this feature monitors your cluster for number of nodes, size of partitions, number of partitions and number of leaders within the cluster. It allows you to shift data to create an even workload across your cluster. It also integrates closely with the quotas feature in Apache Kafka to dynamically throttle data balancing traffic. The Auto Data Balancer allows you to make your Kafka cluster efficient, without the risks of moving partitions by hand."
Narkhede also announced that going forward, future editions of the Confluent Platform will be split into a pure open source distributions and an enhanced enterprise offering, staring with Confluent 3.1 expected at the end of next month.
'Apache Kafka on Heroku is Now Generally Available'
Heroku, a Salesforce company, provides a
cloud-based platform to help organizations build, deploy, monitor and scale apps, using programming languages like Node, Ruby, Java, Scala and PHP.
By supplying Kafka as a service, Heroku helps developers create today's modern event-based systems and architectures, the company said.
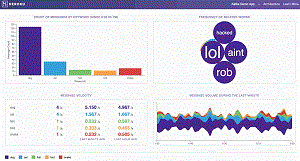 [Click on image for larger animated view.]
Kafka on Heroku in Animated Action (source: Heroku)
[Click on image for larger animated view.]
Kafka on Heroku in Animated Action (source: Heroku)
"At Heroku, we want to make the power of this increasingly important model available to a broader range of developers, allowing them to build evented applications without the cost and complexity of managing infrastructure services," Heroku exec Rand Fitzpatrick said today in a blog post. "Today we are making a big step towards that goal with the general availability of Apache Kafka on Heroku.
"Kafka is the industry-leading open source solution for delivering data-intensive applications and managing event streams, and is backed by an active open source community and ecosystem. By combining the innovation of the Kafka community with Heroku's developer experience and operational expertise, we hope to make this compelling technology even more vibrant and widely adopted, and to enable entirely new use cases and capabilities."
Fitzpatrick said its offering includes features such as: automated operations; simplified configuration; service resiliency, upgrades and regions; a developer experience enhanced with a dashboard, which "provides both visibility into the utilization and behavior of a given Kafka cluster, as well as a simple configuration and management UI."
And More
Kafka was also featured in announcements and presentations from other companies at the New York conference, such as Pentaho, MapR Technologies, MemSQL, Lightbend and others. Stay tuned for a wrap-up of all the Big Data news.
About the Author
David Ramel is an editor and writer at Converge 360.