News
Apache Spark Updates Highlight Latest MapR Ecosystem Pack
- By David Ramel
- April 11, 2017
MapR Technologies Inc. announced a new version of its Ecosystem Pack that features enhanced security for the Apache Spark component, along with new Spark connectors for MapR-DB and HBase and more.
The MapR Ecosystem Pack (MEP) is a program that lets developers upgrade various parts of their open source ecosystem stack separately from MapR's core Converged Data Platform. With quarterly updates, it's supposed to help developers keep up with popular projects such as Apache Spark and Apache Drill that are continually upgraded at different times.
In the new MEP 3.0 edition, MapR is keeping up with the popular Spark and Apache Drill projects. Spark is a well-known and widely used Big Data processing engine, and Drill provides a schema-free, low-latency SQL query engine that MapR says can be used for self-service exploration of Big Data.
"The adoption of Spark and Drill continues to advance at a fast pace with enterprises worldwide," said MapR exec Will Ochandarena in a news release yesterday. "With a regular cadence of ecosystem updates that make it easier to adopt for production use, our customers immediately benefit from rapid open source innovation with the reliability, scale and performance of the Converged Data Platform."
MapR has been steadily updating MEP, having late last year boosted its streaming capabilities by adding support for the Apache Kafka project, for example.
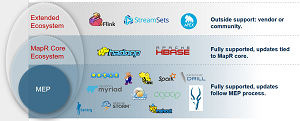 [Click on image for larger view.]
How MEP Fits In (source: MapR Technologies)
[Click on image for larger view.]
How MEP Fits In (source: MapR Technologies)
The new MEP 3.0 supports Spark 2.1.0, a release that MapR said focuses on security and stability for enterprise implementations. Specifically, the company said Spark 2.1.0 provides:
- Scalable partition handling
- Data Type APIs graduate to "stable"
- More than 1,200 fixes on the Spark 2.X line
- Secure connections using MapR-SASL in addition to Kerberos for inbound client connections to the Spark Thrift server and Spark connections to Hive Metastore
- Support for impersonation on SELECT statements
Besides the Spark functionality, other updates in MEP 3.0 include:
- Apache Drill 1.10 -- enhancements around BI tool integration, end-to-end security and performance
- Apache Hive 2.1.1 -- significant performance improvements for data processing and querying
- MapR Streams – new APIs for C and Python applications
- MapR Installer – added features to simplify upgrades and add-ons
- Native Spark connector for MapR-DB JSON -- tight integration results in greater efficiency when MapR-DB records are part of a real-time pipeline
Regarding the latter item, MapR's Rachel Silver explained more in a blog post. "This Native Spark Connector for MapR-DB JSON is a new API that makes it easier to build real-time or batch pipelines between your data and MapR-DB and to leverage Spark or Spark Streaming within the pipeline," she said. "Compared to other connectors for MapR-DB -- such as the JDBC connector -- the Native Spark Connector is more efficient, and the code is simpler to write."
About the Author
David Ramel is an editor and writer at Converge 360.