News
Spark Features Added to Redis NoSQL Database
- By David Ramel
- February 2, 2016
Redis Labs Inc. today announced the integration of its namesake NoSQL database with Spark SQL, along with a new Spark-Redis connector said to speed up certain Big Data analytics tasks by 100 times or more.
Redis Labs is the commercial steward of the open source Redis in-memory data structure store. It claims that time-series analytics benchmarking tests show that using Redis as the data store for Apache Spark speeds up processing in certain use cases. That processing can be up to 135 times faster than using Spark with Hadoop Distributed File System (HDFS) and 45 times faster than using Tachyon for an off-heap data store or working with on-heap Spark storage, the company claimed.
The new Spark-Redis connector provides an open source library for reading and writing data from and to a Redis cluster with Spark, which is an incredibly popular processing engine for Big Data. Developed in conjunction with Databricks Inc., it presents Redis data structures -- such as String, Hash, List, Set and Sorted Set -- to Spark as Resilient Distributed Datasets (RDDs). Those Redis data structures can also be accessed via the DataSet API. Developers can use the connector package library stand-alone or with clustered databases, as it reportedly adjusts automatically to resharding and node failure events based on the partitioning scheme.
The integration with Spark SQL -- Spark's module for working with structured data such as that stored in traditional RDBMSes -- provides a standard query interface for accessing Redis data stores via Spark's DataFrame and DataSource APIs.
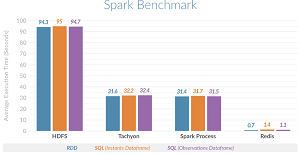 [Click on image for larger view.]
Time-Series Benchmark Testing (source: Reds Labs)
[Click on image for larger view.]
Time-Series Benchmark Testing (source: Reds Labs)
"Big Data is coming of age and customers are demanding that Big Data insights are extracted in real-time," said Yiftach Shoolman, co-founder and CTO of Redis Labs. "This is where Redis Labs fills the gap by delivering both the right performance and optimized distributed memory infrastructure to accelerate Spark. Our goal is to make Redis the de-facto data store for any Spark deployment."
According to 451 Research analyst Matt Aslett, the company might be on the way to attaining that goal. "Apache Spark is becoming a default in-memory engine for high-performance data integration and analytics," Redis Labs quoted Aslett as saying. "The combination of Redis and Spark should enable high-performance, real-time analytics with extremely large and variable datasets."
In addition to the time-series use case, other popular tasks such as graph computation and machine learning are planned to be addressed via future enhancements, Redis Labs said.
About the Author
David Ramel is an editor and writer at Converge 360.