Hadoop and Spark: Friends or Foes?
The first Spark Summit East conference concluded yesterday, just a month after Apache Spark practically stole the show at the Strata+Hadoop World conference, reinvigorating the debate about where the upstart technology fits in with the maturing Apache Hadoop ecosystem.
Certainly Spark is an improvement upon the original MapReduce component of said ecosystem, but there's a growing chorus of debate about whether Spark will mount a challenge to Hadoop itself, becoming its replacement and pre-eminent Big Data analytics tool.
Qubole Inc. works with both technologies and has a unique perspective on the debate. The Mountain View, Calif., company is known for its cloud-based Qubole Data Service (QDS), a self-managed Hadoop-as-a-Service (HaaS) offering.
Just last month, the company incorporated Spark into QDS, adding it to the bevy of Big Data components it works with such as MapReduce, Hive, Pig, Oozie, Sqoop, Presto and so on.
"There is a lot of excitement around Spark because it can give a real advantage in multi-pass iterative machine learning algorithms, as well as interactive data interrogation on in-memory data sets," Qubole CEO and Co-Founder Ashish Thusoo told ADTMag.com. "By many accounts it can tackle these workloads at speeds up to 100 times faster."
 [Click on image for larger view.]
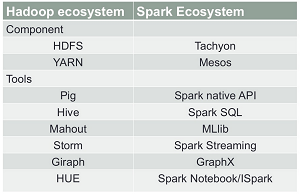
The Respective Landscapes (source: Chicago Hadoop User Group via Slideshare)
[Click on image for larger view.]
The Respective Landscapes (source: Chicago Hadoop User Group via Slideshare)
To review, MapReduce is the original massively scalable, parallel processing framework commonly used with Hadoop and other components such as the Hadoop Distributed File System (HDFS) and YARN. YARN can be described as a large-scale, distributed OS for Big Data implementations -- sometimes referred to as Yet Another Resource Negotiator -- which has been characterized as an improvement upon the MapReduce model.
As Hadoop has matured, the batch-oriented, disk-intensive MapReduce's limitations have become more apparent as Big Data analytics moves to more real-time, streaming processing and advanced implementations such as the aforementioned machine learning.
Spark evolved to address some of these shortcomings, becoming the most active project under the guise of the Apache Software Foundation (ASF) and most active open source Big Data project of any kind. It's commonly praised for its in-memory technology that boosts processing speeds up to hundreds of times over disk-based MapReduce computations in certain applications.
"Spark is a memory-centric data processing framework," explained Gartner Inc. Research Director Nick Heudecker to ADTMag.com. "It doesn't have a file system or a resource manager -- both things it has to get from another environment, like Hadoop or Mesos. Spark is typically faster than MapReduce for iterative processing. Another core difference is programming languages. MapReduce is written in Java, while Spark uses Scala. Scala is generally more fluent than Java, but Scala skills are harder to come by in the market."
"At the highest level, Spark is geared toward in-memory processing and Hadoop (MapReduce) is very disk-dependent," Thusoo explained. "This makes Spark particularly well suited for iterative algorithms that require multiple passes over in-memory data, while Hadoop's designed purpose is to manage very large volumes of data in a batch process workflow. Spark can work on top of Hadoop. They are different on many other levels, including technology maturity and language support."
That language support is also emphasized by Forrester Research Inc. as a strong Spark selling point.
"Spark includes APIs in Java, Scala, and Python that provide over 80 data transformation and action operators that hide the complexity of cluster computing," Forrester analyst Mike Gualtieri said in a report last month titled "Apache Spark Is Powerful and Promising." "Developers and data scientists can use the API and the supported programming language of their choice to develop any arbitrary data processing application, and the Spark engine will figure out how to execute the job efficiently on the cluster. In addition to the core APIs, Spark also includes specialized higher-level tools that can be used separately or together to build applications."
Also able to be used separately is Spark itself, with no required dependence upon Hadoop. "We are seeing a lot of applications in non-Hadoop environments, such as the public cloud," Databricks Inc. exec Kavitha Mariappan told ADTMag.com. Commercial Spark steward Databricks was founded by the original creators of Spark working at the UC Berkeley AMPLab.
 [Click on image for larger view.]
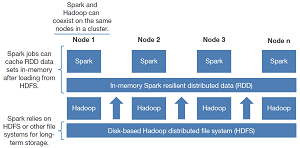
Spark and Hadoop Can Coexist in the Same Cluster (source: Forrester Research Inc.)
[Click on image for larger view.]
Spark and Hadoop Can Coexist in the Same Cluster (source: Forrester Research Inc.)
Databricks -- with definite "skin in the game" in the form of its Spark-based "zero management" cloud platform -- expounded upon the benefits of Spark over Hadoop/MapReduce.
"The design of Hadoop MapReduce is over 10 years old, and MapReduce as a project is no longer rapidly evolving," Mariappan said. "Spark is fast subsuming it, and doing much more beyond what MapReduce ever could. In fact, many data processing jobs that were originally written in Hadoop MapReduce are being rewritten for Spark today."
While affirming that Spark will continue to play a big role in the Big Data arena, Mariappan stopped short of saying Spark will overtake Hadoop. "The goal of the Spark project is not to threaten or replace Hadoop, but rather integrate and interpolate well with a variety of systems (including Hadoop) to make it easier to build more powerful applications," she said.
Qubole, noting that it's "tool-agnostic," also isn't predicting that Spark will take over the Big Data world, either.
"We don't see that Spark has to win at the expense of MapReduce," Qubole's Thusoo told ADTMag.com. "For now, there are still distinct tradeoffs in terms of use cases, infrastructure cost and relative maturity."
Heudecker agreed. "It's easy to see Spark becoming the successor to MapReduce in the Hadoop ecosystem, but I'm not sure it's about picking one over the other," the Gartner analyst said. "While Spark is very early in its development, it represents the most substantial challenge to the incumbent Hadoop distributors. Recent benchmarks indicate Spark is substantially faster than MapReduce, using less hardware.
"Hadoop vendors count on selling more nodes and larger clusters," Heudecker continued. "Anything reducing the number of nodes required to perform the same tasks threatens not just numerous business models, but Hadoop's fundamental value proposition of being the primary, lower-cost alternative to traditional information infrastructure. Today, Spark is too immature to be considered a replacement for Hadoop, but it looks like the future."
Qubole, for its part, sees that Big Data future in the cloud.
"We actually take the position that there is a shortcoming in all these tools [MapReduce, Spark, Presto, Hive and so on], in the context of a larger business audience, and that is accessibility," Thusoo said. "The rate of failure with in-house corporate Hadoop projects is absolutely astounding. Besides poor scoping, as so much of this technology is new, a company really needs to assemble a unique, expensive and rare set of deep skills in both infrastructure building and programming before anyone ever gets to data science. This is what we set out to address in creating Qubole for Big Data in the cloud."
Heudecker also lended weight to the view that Hadoop hasn't fulfilled all of its much-hyped promises yet. "Thru 2018, 70 percent of Hadoop deployments will not meet cost savings & revenue generation objectives due to skills & integration challenges," he recently tweeted.
Echoing the view that Big Data as a concept is dying -- espoused by fellow Gartner analyst Donald Feinberg and others -- Heudecker denied that Spark is the future of Big Data.
"No. The future of Big Data is just data," Heudecker said. "It will likely take another five years, but Big Data is becoming the new normal. Spark may play a role, but it wasn't the first data processing framework and it won't be the last."
Posted by David Ramel on March 20, 2015