News
What's Driving Apache Spark Growth? SQL, Streaming and Machine Learning
- By David Ramel
- October 3, 2016
Databricks Inc., the primary commercial steward behind the popular open source Apache Spark data processing framework for Big Data analytics, published a new report indicating the technology is still red-hot, driven by more use of SQL, streaming analytics and machine learning.
The company this summer polled more than 900 organizations and solicited data from 1,615 respondents -- mostly Spark users -- coming from the ranks of data scientists, data engineers, architects and others, and last week published the results in the Apache Spark Survey 2016 Report (free download upon providing registration info).
The report follows up on a similar survey last year, confirming the technology's widespread popularity as the most active open source project in the Big Data space.
"As in 2015, which was a tremendous year in growth for Apache Spark, this year, too, its growth remains unabated -- not only in areas like the public cloud, but also with the increased use of Spark Streaming and the use of machine learning," the report states. "2016 also shows Spark's robust adoption across a variety of organizations and users from many functional roles to build complex solutions, using multiple Spark components."
Databricks identified several of the fastest-growing areas in the Spark ecosystem as Spark SQL users (up 67 pecrent), streaming users (up 57 percent) and advanced analytics users (leveraging the machine learning library, MLlib, up 38 percent). The No. 1 growth area, though, was the use of the DataFrame API, introduced by Databricks early last year.
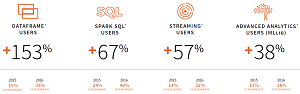 [Click on image for larger view.]
Fastest Growing Areas in Spark (source: Databricks)
[Click on image for larger view.]
Fastest Growing Areas in Spark (source: Databricks)
"In Spark, a DataFrame is a distributed collection of data organized into named columns," the company said at the time. "It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases or existing [Resilient Distributed Dataset (RDD)]."
In the programming department, the survey noted a surge of Python developers (up from 58 percent last year to 62 percent this year) and SQL (up from 36 percent last year to 44 percent this year) using Spark, at the expense of Scala (down from 71 percent last year to 65 percent this year) and Java (down from 31 percent last year to 29 percent this year).
Adding some context to that finding, Databricks said: "Usage of Spark in Python, SQ, and R increased, while Scala and Java usage decreased. This indicates that more data analysts are drawn to Spark from areas other than pure data engineering, suggesting that Spark usage is expanding to new and diverse users."
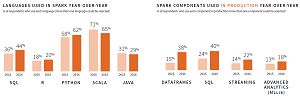 [Click on image for larger view.]
Popular Languages, Components (source: Databricks)
[Click on image for larger view.]
Popular Languages, Components (source: Databricks)
It was the increased usage of SQL, streaming and ML that caught Databricks eye, though.
"Since last year, the use of Spark components in production has increased, especially in Spark Streaming and advanced analytics with Apache Spark MLlib (machine learning)," the report said. "This corroborates with the observation in this report about increased interest among Spark users to build real-time streaming applications with Spark Streaming, using multiple components, including MLlib."
More than half of survey respondents said streaming is "vital and important" for developing real-time application such as recommendation engines and security solutions such as fraud detection.
As far as SQL, the survey indicated 82 percent of respondents us open source SQL databases in their Spark work, followed by key-value NoSQL data stores (73 percent) and proprietary SQL databases (58 percent).
Other survey findings include:
- Deployment in public clouds has increased by 10 percent over last year (51 percent to 61 percent of respondents).
- On-premises deployments decreased, with Mesos falling from 11 percent last year to 7 percent this year, YARN falling from 40 percent last year to 36 percent this year, and standalone implementations falling from 48 percent last year to 42 percent this year.
- Windows users in development grew from 23 percent of respondents last year to 32 percent this year.
- Linux/Unix users fell from 75 percent last year to 74 percent this year.
- Mac OS X users fell from 47 percent last year to 38 percent this year.
- Scala, though its percentage of users has fallen (see above), is still the No. 1 language (used by 65 percent of respondents), followed by Python (62 percent), SQL (44 percent), Java (29 percent) and R (20 percent).
- Business/customer intelligence was the No. 1 use case (68 percent), followed by data warehousing (52 percent), real-time/streaming solutions (45 percent), recommendation engines (40 percent) and log processing (37 percent).
- Performance is the most important feature of Spark (91 percent), followed by advanced analytics (82 percent), ease of programming (76 percent), ease of deployment (69 percent) and real-time streaming (51 percent).
Databricks said the Spark project this year enjoyed contributions from more than 1,000 people, compared with 600 last year. Meetup members were up 240 percent, Spark Summit attendees were up 30 percent and the number of companies represented at those summits was up 57 percent.
"Spark today remains the most active open source project in Big Data," the company said. "With such large numbers of contributors and organizations investing in Spark's future development, it has engaged a community of developers globally."
About the Author
David Ramel is an editor and writer at Converge 360.