News
RainStor Upgrades Big Data Archive App for Hadoop 2.0
- By David Ramel
- June 24, 2014
Big Data database provider RainStor Inc. today released a new version of its software that includes an archive application for storing data long-term on Hadoop 2.0.
The company is known for managing historical data for analysis and policy-compliant retention with its Active Archive technology.
With the new RainStor 6, the company said its open, standards-based technology that's ideal for running on the Hadoop Distributed File System (HDFS) can take advantage of some of the latest Hadoop innovations. This includes support for YARN, an upgrade sometimes referred to as a "data operating system" that improves upon the original MapReduce component central to the Hadoop ecosystem.
"RainStor integrates with YARN to ensure full co-operation in managing resources across a busy Hadoop cluster," the company said. "From a cluster monitoring perspective, RainStor integrates with Apache Ambari. RainStor also provides connectivity through HCatalog, the de facto interface to relational data. These capabilities offer users increased flexibility in selecting the tools that best fit their needs."
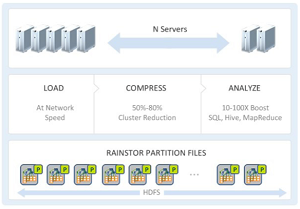 [Click on image for larger view.]
The RainStor Hadoop solution (source: RainStor)
[Click on image for larger view.]
The RainStor Hadoop solution (source: RainStor)
RainStor 6 is certified on the Hortonworks 2.1 and Cloudera 5 Hadoop distributions.
The new archive application builds on the company's SQL-on-Hadoop stack by featuring XQuery, a database query and functional programming language.
"Users benefit from a 10-100X-query boost using native SQL against a mix of structured, semi-structured data and documents in the same cluster," RainStor said. "Performance improvements also apply to queries against Hive, Pig and MapReduce. An archive on Hadoop should achieve performance levels on par with the source environment, which is typically a data warehouse."
RainStor said the new release also provides greater governance control of Hadoop data, with retention and expiry data management life-cycle features.
Organizations deploy archives when they have growing data that must be kept for continuing business queries or when governance rules dictate that data be online and accessible for certain periods of time. RainStor said users might need access to multiple years of raw detailed data to glean business insights and derive business value.
"With a rules-based workflow you specify a record or groups of records to keep or delete, as they are loaded," the company said. "Adhering to data governance practices has become a critical requirement as volumes grow, and now you have greater control with your data in Hadoop, which eliminates time-consuming manual intervention or lost data."
About the Author
David Ramel is an editor and writer at Converge 360.